Weaponizing the Weather
“Intervention in atmospheric and climatic matters . . . will unfold on a scale difficult to imagine at present. . . . this will merge each nation’s affairs with those of every other, more thoroughly than the threat of a nuclear or any other war would have done.” — J. von Neumann
Disclaimer: This is just me exploring a topic that I’m generally clueless on, explicitly because I’m clueless on it. My views and the research discussed here has nothing to do with my work for the DoD.
Why do we care?
Attempting to control the weather is older than science itself. While it is common today to perform cloud seeding to increase rain or snow, weather modification has the potential to prevent damaging weather from occurring; or to provoke damaging weather as a tactic of military or economic warfare. This scares all of us, including the UN who banned weather modification for the purposes of warfare in response to US actions in Vietnam to induce rain and extend the East Asian monsoon season (see operation popeye). Unfortunately, this hasn’t stopped Russia and China from pursuing active weather modification programs with China generally regarded as the largest and most active. While Russia is famous for sophisticated cloud-seeding in 1986 to prevent radioactive rain from the Chernobyl reactor accident from reaching Moscow, see China Leads the Weather Control Race and China plans to halt rain for Olympics to understand the extent of China’s efforts in this area.
The Chinese have been tinkering with the weather since the late 1950s, trying to bring rains to the desert terrain of the northern provinces. Their bureau of weather modification was established in the 1980s and is now believed to be the largest in the world. It has a reserve army of 37,000 people, which might sound like a lot, until we consider the scale of an average storm. The numbers that describe weather are big. At any instant there are approximately 2,000 thunderstorms and every day there are 45,000 thunderstorms, which contain some combination of heavy rain, hail, microbursts, wind shear, and lightning. The energy involved is staggering: a tropical storm can have an energy equal to 10,000 one-megaton hydrogen bombs. A single cloud contains about a million pounds of water so a mid-size storm would contain about 3 billion pounds of water. If anyone ever figures out how to control all this mass and energy they would make an excellent bond villain.
The US government has conducted research in weather modification as well. In 1970, then ARPA Director Stephen J. Lukasik told the Senate Appropriations Committee: “Since it now appears highly probable that major world powers have the ability to create modifications of climate that might be seriously detrimental to the security of this country, Nile Blue [a computer simulation] was established in FY 70 to achieve a US capability to (1) evaluate all consequences of of a variety of possible actions … (2) detect trends in in the global circulation which foretell changes … and (3) determine if possible , means to counter potentially deleterious climatic changes … What this means is learning how much you have to tickle the atmosphere to perturb the earth’s climate.” Sounds like a reasonable program for the time.
Military applications are easy to think up. If you could create a localized could layer, you could decrease performance of ground and airborne IRSTs particularly in the long-wave. (Cloud mean-diameter is typically 10 to 15 microns.) You could send hurricanes toward your adversary or increase the impact of an all weather advantage. (Sweet.) You could also do more subtle effects such as inuring the atmosphere towards your communications technology or degrade the environment to a state less optimal for an adversary’s communications or sensors. Another key advantage would be to make the environment unpredictable. Future ground-based sensing and fusing architectures such as multi-static and passive radars rely on a correctly characterized environment that could be impacted by both intense and unpredictable weather.
Aside from military uses, climate change (both perception and fact) may drive some nations to seek engineered solutions. Commercial interests would welcome the chance to make money cleaning up the mess they made money making. And how are we going to sort out and regulate that without options and deep understanding? Many of these proposals could have dual civilian and military purposes as they originate in Cold War technologies. As the science advances, will we be able to prevent their renewed use as weapons? Could the future hold climatological conflicts, just as we’ve seen cyber warfare used to presage invasion as recently seen between Ukraine and Russia? If so, climate influence would be a way for a large state to exert an influence on smaller states.
Considering all of this, it would be prudent to have a national security policy that accounts for weather modification and manipulation. Solar radiation management, called albedo modification, is considered to be a potential option for addressing climate change and one that may get increased attention. There are many research opportunities that would allow the scientific community to learn more about the risks and benefits of albedo modification, knowledge which could better inform societal decisions without imposing the risks associated with large-scale deployment. According to Carbon Dioxide Removal and Reliable Sequestration (2015) by the National Academy of Sciences, there are several hypothetical, but plausible, scenarios under which this information would be useful. They claim (quoting them verbatim):
- If, despite mitigation and adaptation, the impacts of climate change still become intolerable (e.g., massive crop failures throughout the tropics), society would face very tough choices regarding whether and how to deploy albedo modification until such time as mitigation, carbon dioxide removal, and adaptation actions could significantly reduce the impacts of climate change.
- The international community might consider a gradual phase-in of albedo modification to a level expected to create a detectable modification of Earth’s climate, as a large-scale field trial aimed at gaining experience with albedo modification in case it needs to be scaled up in response to a climate emergency. This might be considered as part of a portfolio of actions to reduce the risks of climate change.
- If an unsanctioned act of albedo modification were to occur, scientific research would be needed to understand how best to detect and quantify the act and its consequences and impacts.
What has been done in the past?
Weather modification was limited to magic and prayers until the 18th century when hail cannons were fired into the air to break up storms. There is still an industrial base today if you would like to have your own hail cannon. Just don’t move in next door if you plan on practicing.

(Not so useful) Hail Cannons
Despite their use on a large scale, there is no evidence in favor of the effectiveness of these devices. A 2006 review by Jon Wieringa and Iwan Holleman in the journal Meteorologische Zeitschrift summarized a variety of negative and inconclusive scientific measurements, concluding that “the use of cannons or explosive rockets is waste of money and effort”. In the 1950s to 1960s, Wilhelm Reich performed cloudbusting experiments, the results of which are controversial and not widely accepted by mainstream science.
However, during the cold war the US government committed to a ambitious experimental program named Project Stormfury for nearly 20 years (1962 to 1983). The DoD and NOAA attempted to weaken tropical cyclones by flying aircraft into them and seeding them with silver iodide. The proposed modification technique involved artificial stimulation of convection outside the eye wall through seeding with silver iodide. The artificially invigorated convection, it was argued, would compete with the convection in the original eye wall, lead to reformation of the eye wall at larger radius, and thus produce a decrease in the maximum wind. Since a hurricane’s destructive potential increases rapidly as its maximum wind becomes stronger, a reduction as small as 10% would have been worthwhile. Modification was attempted in four hurricanes on eight different days. On four of these days, the winds decreased by between 10 and 30%. The lack of response on the other days was interpreted to be the result of faulty execution of the experiment or poorly selected subjects.
These promising results have, however, come into question because recent observations of unmodified hurricanes indicate: I) that cloud seeding has little prospect of success because hurricanes contain too much natural ice and too little super cooled water, and 2) that the positive results inferred from the seeding experiments in the 1960s probably stemmed from inability to discriminate between the expected effect of human intervention and the natural behavior of hurricanes. The legacy of this program is the large global infrastructure today that routinely flies to inject silver iodide to cause localized rain with over 40 countries actively seeding clouds to control rainfall. Unfortunately, we are still pretty much helpless in the face of a large hurricane.
That doesn’t mean the Chinese aren’t trying. In 2008, China assigned 30 airplanes, 4,000 rocket launchers, and 7,000 anti-aircraft guns in an attempt to stop rain from disrupting the 2008 Olympics by shooting various chemicals into the air at any threatening clouds in the hopes of shrinking rain drops before they reached the stadium. Due to the difficulty of conducting controlled experiments at this scale, there is no way to know if this was effective. (Yes, this is the country that routinely bulldozes entire mountain ranges to make economic regions.)
But the Chinese aren’t the only ones. In January, 2011, several newspapers and magazines, including the UK’s Sunday Times and Arabian Business, reported that scientists backed by Abu Dhabi had created over 50 artificial rainstorms between July and August 2010 near Al Ain. The artificial rainstorms were said to have sometimes caused hail, gales and thunderstorms, baffling local residents. The scientists reportedly used ionizers to create the rainstorms, and although the results are disputed, the large number of times it is recorded to have rained right after the ionizers were switched on during a usually dry season is encouraging to those who support the experiment.
While we would have to understand the technology very well first and have a good risk mitigation strategy, I think there are several promising technical areas that merit further research.
What are the technical approaches?
So while past experiments are hard to learn much from and far from providing the buttons to control the weather, there are some promising technologies I’m going to be watching. There are five different technical approaches I was able to find:
- Altering the available solar energy by introducing materials to absorb or reflect sunshine
- Adding heat to the atmosphere by artificial means from the surface
- Altering air motion by artificial means
- Influencing the humidity by increasing or retarding evaporation
- Changing the processes by which clouds form and causing precipitation by using chemicals or inserting additional water into the clouds
In these five areas, I see several technical applications that are both interesting and have some degree of potential utility.
Modeling
Below is the 23-year accuracy of the U.S. GFS, the European ECMWF, the U.K. Government’s UKMET, and a model called CDAS which has never been modified, to serve as a “constant.” As you would expect, model accuracy is gradually increasing (1.0 is 100% accurate). Weather models are limited by computation and the scale of input data: for a fixed amount of computing power, the smaller the grid (and more accurate the prediction), the smaller time horizon for predictions. As more sensors are added and fused together, accuracy will keep improving.
Weather requires satellite and radar imagery that are truly on the very small scale. Current accuracy is an effective observation spacing of around 5 km. Radar data are only available to a fairly short distance from the coast. Satellite wind measurements can only resolve detail on about a 25 km scale. Over land, data from radar can be used to help predict small scale and short lived detail.
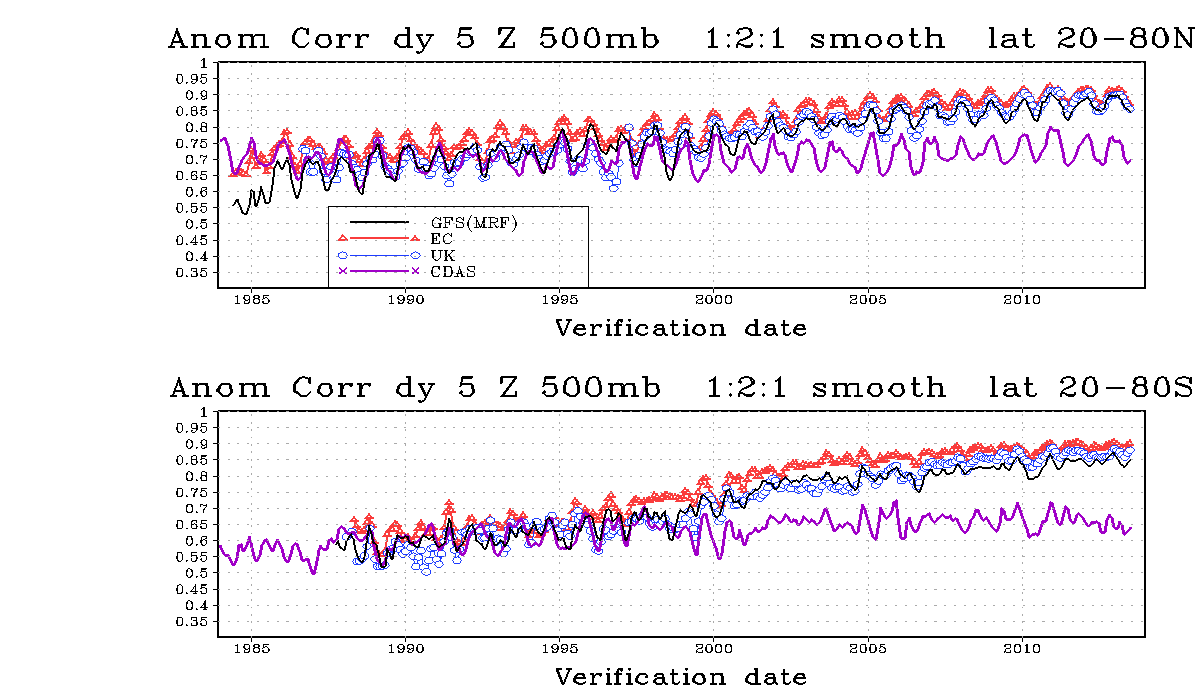
Weather Model Accuracy over Time
Modeling is important, because understanding is necessary for control. With increased accuracy, we can understand weather’s leverage points and feedback loops. This knowledge is important, because increased understanding would enable applying the least amount of energy where it matters most. Interacting with weather on a macro scale is both cost prohibitive and extremely complex.
Ionospheric Augmentation
Over the horizon radars (commonly called OTHR) have the potential to see targets hundreds of miles away because they aren’t limited by their line of sight like conventional microwave radars. They accomplish this by bouncing off the horizon, but this requires a sufficiently dense ionosphere that isn’t always there. Since the ionosphere is ionized by solar radiation, the solar radiation is stronger when the earth is more tilted towards the sun in the summer. To compensate for this, artificial ionospheric mirrors could bounce HF signals more consistently and precisely over broader frequencies. Tests have shown that these mirrors could theoretically reflect radio waves with frequencies up to 2 GHz, which is nearly two orders of magnitude higher than waves reflected by the natural ionosphere. This could have significant military applications such as low frequency (LF) communications, HF ducted communications, and increased OTHR performance.
This concept has been described in detail by Paul A. Kossey, et al. in a paper entitled “Artificial Ionospheric Mirrors.” The authors describe how one could precisely control the location and height of the region of artificially produced ionization using crossed microwave beams, which produce atmospheric breakdown. The implications of such control are enormous: one would no longer be subject to the vagaries of the natural ionosphere but would instead have direct control of the propagation environment. Ideally, these artificial mirrors could be rapidly created and then would be maintained only for a brief operational period.
Local Introduction of Clouds
There are several methods for seeding clouds. The best-known dissipation technique for cold fog is to seed it from the air with agents that promote the growth of ice crystals. They include dropping pyrotechnics on lop of existing clouds. penetrating clouds, with pyrotechnics and liquid generators, shooting rockets into clouds, and working from ground-based generators. Silver iodide is frequently used lo cause precipitation, and effects usually are seen in about thirty minutes. Limited success has been noted in fog dispersal and improving local visibility through introduction of hygroscopic substances.
However, all of these techniques seem like a very inexact science and 30 minutes remains far from the timescales needed for clouds on demand. From my brief look at it, we are just poking around in cloud formation. For the local introduction of clouds to be useful in military applications, there have to be a suite of techniques robust to changing weather. More research in this area might be able to effect chain reactions to cause massive cloud formations. Real research in this area could help it emerge from pseudo-science. There is a lot of it in this area. This Atlantic article titled Dr. Wilhelm Reich’s Orgasm-Powered Cloudbuster is pretty amusing and pretty indicative of the genre.

A cloud gun that taps into an “omnipresent libidinal life force responsible for gravity, weather patterns, emotions, and health”
Fog Removal
Ok, so no-one can make clouds appear on demand in a wide range of environments, but is technology better when it comes to removing fog? The best-known dissipation technique is heating because a small temperature increase is usually sufficient to evaporate fog. Since heating over a very wide scale usually isn’t practical, the next most effective technique is hygroscopic seeding. Hygroscopic seeding uses agents that absorb water vapor. This technique is most effective when accomplished from the air but can also be accomplished from the ground. Optimal results require advance information on fog depth, liquid water content, and wind.
In the 20th century several methods have been proposed to dissipate fog. One of them is to burn fuel along the runway, heat the fog layer and evaporate droplets. It has been used in Great Britain during World War II to allow British bombers returning from Germany to land safely in fog conditions. Helicopters can dissipate fog by flying slowly across the top surface and mix warm dry air into the fog. The downwash action of the rotors forces air from above into the fog, where it mixes, producing lower humidity and causing the fog droplets to evaporate. Tests were carried out in Florida and Virginia, and in both places cleared areas were produced in the helicopter wakes. Seeding with polyelectrolytes causes electric charges to develop on drops and has been shown to cause drops to coalesce and fallout. Other techniques that have been tried include the use of high-frequency (ultrasonic) vibrations, heating with laser rays and seeding with carbon black to alter the radiative properties1.
However, experiments have confirmed that large-scale fog removal would require exceeding the power density exposure limit of $100 \frac{\text{watt}}{m^2}$ and would be very expensive. Field experiments with lasers have demonstrated the capability to dissipate warm fog at an airfield with zero visibility. This doesn’t mean that capability on a smaller scale isn’t possible. Generating $1 \frac{\text{watt}}{cm^2}$, which is approximately the US large power density exposure limit, raised visibility to one quarter of a mile in 20 seconds. Most efforts have been made on attempts to increase the runway visibility range on airports, since airline companies face millions of dollars loss every year due to fog appearance on the runway. This thesis examines in the issue in depth.
Emerging Enabling Technologies
In looking at this topic, I was able to find several interesting technologies that may develop and make big contributions to weather research.
Carbon Dust
Just as a black tar roof easily absorbs solar energy and subsequently radiates heat during a sunny day, carbon black also readily absorbs solar energy. When dispersed in microscopic form in the air over a large body of water, the carbon becomes hot and heats the surrounding air, thereby increasing the amount of evaporation from the water below. As the surrounding air heats up, parcels of air will rise and the water vapor contained in the rising air parcel will eventually condense to form clouds. Over time the cloud droplets increase in size as more and more water vapor condenses, and eventually they become too large and heavy to stay suspended and will fall as rain. This technology has the potential to trigger localized flooding and bog down troops and their equipment.
Nanotech
Want to think outside the box? Smart materials based on nanotechnology are currently being developed with processing capability. They could adjust their size to optimal dimensions for a given fog seeding situation and even make continual adjustments. They might also enhance their dispersal qualities by adjusting their buoyancy, by communicating with each other, and by steering themselves within the fog. If successful, they will be able to provide immediate and continuous effectiveness feedback by integrating with a larger sensor network and could also change their temperature and polarity to improve their seeding effects.
If we combine this with high fidelity models, things can get very interesting. If we can model and understand the leverage points of a weather system, nano-clouds may be able to have an dramatic effect. Nanotechnology also offers possibilities for creating simulated weather. A cloud, or several clouds, of microscopic computer particles, all communicating with each other and with a larger control system could mimic the signatures of specific weather patterns if tailored to the parameters of weather models.
High power lasers
The development of directed radiant energy technologies, such as microwaves and lasers, could provide new possibilities. Everyone should hate firing rockets and chemicals into the atmosphere. The advent of ultrashort laser pulses and the discovery of self-guided ionized filaments (see Braun et al., 1985) might provide the opportunity. Jean-Pierre Wolf has used using ultrashort laser pulses to create lightning and cue cloud formation. Prof Wolf says, “We did it on a laboratory scale, we can already create clouds, but not on a macroscopic scale, so you don’t see a big cloud coming out because the laser is not powerful enough and because of a lot of technical parameters that we can’t yet control,” from this cnn article.
What now?
So we have all the elements of scientific discipline and could use a national strategy in this area that includes the ethics, policy, technology and military employment doctrine. The military and civilian community already invests heavily in sensors and modeling of weather effects. These should be coupled with feasible excitation mechanisms to create a tight innovation loop. Again, this area is sensitive and politically charged, but there is a clear need to pull together sensors, processing capability and excitation mechanisms to ensure we have the right responses and capabilities. With such a dubious and inconclusive past, is there a potential future for weather modification? I think we have a responsibility for pursing knowledge even in areas where the ethical boundaries are not well established. Ignorance is never a good strategy. Just because we might open Pandora’s box, doesn’t mean that a less morally responsible nation or group won’t get there first. We can always abstain from learning a new technology, but if we are caught by surprise, we won’t have the knowledge to develop a good counter-strategy.
References
- http://csat.au.af.mil/2025/volume3/vol3ch15.pdf
- http://www.wired.com/2009/12/military-science-hack-stormy-skies-to-lord-over-lightning/
- PROSPECTS FOR WEATHER MODIFICATION
- DUMBAI, MA, et al. “ORGANIC HEAT-TRANSFER AGENTS IN CHEMICAL-INDUSTRY.” KHIMICHESKAYA PROMYSHLENNOST 1 (1990): 10-15. ↩













