When President Trump signed the GENIUS Act on July 18, 2025, he didn’t just regulate stablecoins—he legitimized an entire technology stack that will become core infrastructure for defense and intelligence agencies. By requiring full liquid reserves and exempting compliant stablecoins from securities regulations, the Act transforms what was once speculative technology into government-grade payment and settlement infrastructure.
This matters because modern military operations aren’t starved for bandwidth and processing power—they need immutable state, enforceable trust, and precise data distribution. The same technology that powers a dollar-pegged stablecoin can lock mission events in seconds, encode rules of engagement in self-executing code, and prove compliance without compromising operational security.
Command and control breaks when everyone maintains their own version of “truth.” Byzantine fault-tolerant consensus—the same mechanism that prevents double-spending in stablecoins—forces independent nodes to agree on each state change before it’s recorded. No more reconciliation queues. No more debating which ROE update is authoritative. Just a single, cryptographically locked sequence of events that can’t be quietly rewritten.
With that single, tamper‑proof log in place, autonomous systems can graduate from lone‑wolf behaviors to coordinated swarms: the ledger’s state becomes the authoritative “leader,” while each drone, satellite, or ground robot is a “follower” that subscribes to—and writes into—the same stream. AI planners can post composite tasks (sensor → shooter chains, refuel rendezvous, med‑evac corridors) as smart‑contract directives; individual platforms claim subtasks, stake cryptographic commitments, and update status the moment they act. Because every node sees identical state within seconds, hand‑offs and deconfliction happen in code, not over voice nets, and higher‑level orchestration engines can reason over the evolving mission graph in real time. The result is multi‑platform C2 where machines negotiate roles, verify execution, and re‑task themselves under a commander’s intent—while commanders and auditors retain an immutable play‑by‑play of who led, who followed, and whether the AI kept faith with policy.
But this tech can do more than just enable coordinated higher level autonomy. Supply chains fail when we can’t prove provenance. The tokenization standards legitimized by the GENIUS Act give every part, payment, and piece of data a cryptographic birth certificate. A counterfeit component breaks the chain instantly. Payment releases automatically when secure oracles confirm delivery and compliance. Cash cycles drop from 60-120 days to near real-time.
Zero-trust architectures stall without programmable policy. Smart contracts—now legally deployable for government use—convert access control from organizational charts into mathematical proofs. A fire mission only executes if the required cryptographic signatures align. Coalition partners can verify actions without seeing raw intelligence.
Before the GENIUS Act, stable‑coin rails and tokenised provenance rarely moved beyond DARPA demos because the scale‑up money wasn’t there: mission engineers could prove value in a sandbox, but CFOs and contracting officers lacked a legally accepted funding mechanism and a clear path to classify the R&D spend. The existence of large‑volume pilots—and the capital that follows—will harden the stack, integrate it with legacy systems, and drive down technical risk for the war‑fighter.
Now, with explicit statutory protection for properly-backed digital assets, defense contractors can build at scale. The same legal framework that protects a stablecoin’s dollar peg protects a tokenized part inventory, a programmable budget line, or a cryptographically-governed sensor feed.
The Act doesn’t just permit this infrastructure—it demands it. Full reserve requirements and regular attestations? That’s exactly the level of auditability the DoD needs for financial management. Bankruptcy-remote custody structures? Perfect for protecting government assets in contractor systems. Real-time settlement with cryptographic finality? Precisely what accelerated kill chains require.
The GENIUS Act creates a rare alignment between financial innovation and national security needs. The question isn’t whether this technology will reshape defense operations—it’s who will build it.
This will intersect with formal methods in a powerful way. Recent breakthroughs in large‑scale formal verification—driven by Amazon’s Byron Cook and Michael Hicks—slot perfectly into this Merkle‑anchored world: their push‑button model‑checking and property‑based compilation pipelines can exhaustively prove that a smart contract (or autonomous‑agent policy) preserves invariants like “never fire without dual‑key authorization” or “funds only move when supply‑chain proofs are valid” before the code ever deploys, while the Merkle tree records every compiled binary and configuration hash so field auditors can show the running system is exactly the one that passed the proofs.
Silicon Valley fintechs are already racing to capture the civilian market. They’ll build the protocols, control the standards, and rent access back to the government. Or defense primes can recognize this moment: the regulatory green light to build sovereign, military-grade distributed systems that we control from the ground up.
The experimental phase is over. The GENIUS Act provides the legal foundation. The technology works at massive scale. The operational need is real.
The only question left is whether the national security establishment will seize this opportunity to build its own cryptographic infrastructure—or wake up in five years dependent on systems designed for retail banking, hoping they can be retrofitted for combat.
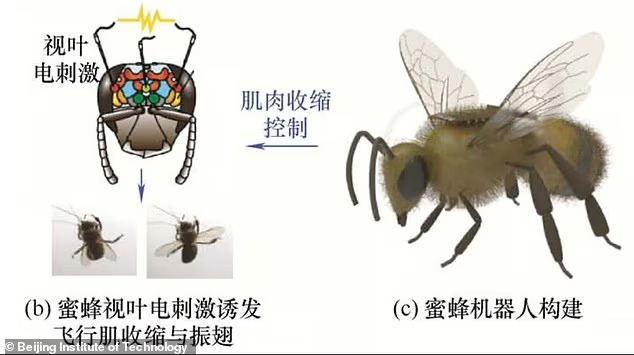
Researchers in China are crafting cyborg bees by fitting them with incredibly thin neural implants (article: Design of flight control system for honeybee based on EEG stimulation). The story isn’t that biology replaces electronics; it’s that biology supplies free actuation, sensing, and ultra low power computation that we can piggyback on with just enough silicon to plug those abilities into our digital world. Through leveraging natural flight capabilities and endurance of biological hosts, you have an ideal covert reconnaissance or delivery platform ideal for military surveillance, counterterrorism operations, physically hacking hardware and disaster relief missions where traditional drones would be too conspicuous or lack the agility to navigate complex environments.
So, there are lots of news articles on this, but the concept of miniature flying machines is far from new. For over a decade before projects like Harvard’s pioneering RoboBee took flight in 2007, researchers were already delving into micro-aerial vehicles (MAVs), driven by the quest for stealthy surveillance and other specialized applications. Early breakthroughs, such as the untethered flight of the Delft University of Technology’s “DelFly,” laid crucial groundwork, proving that insect-scale flight was not just a sci-fi dream but an achievable engineering challenge. This long history underscores a persistent, fascinating pursuit: shrinking aerial capabilities to an almost invisible scale.
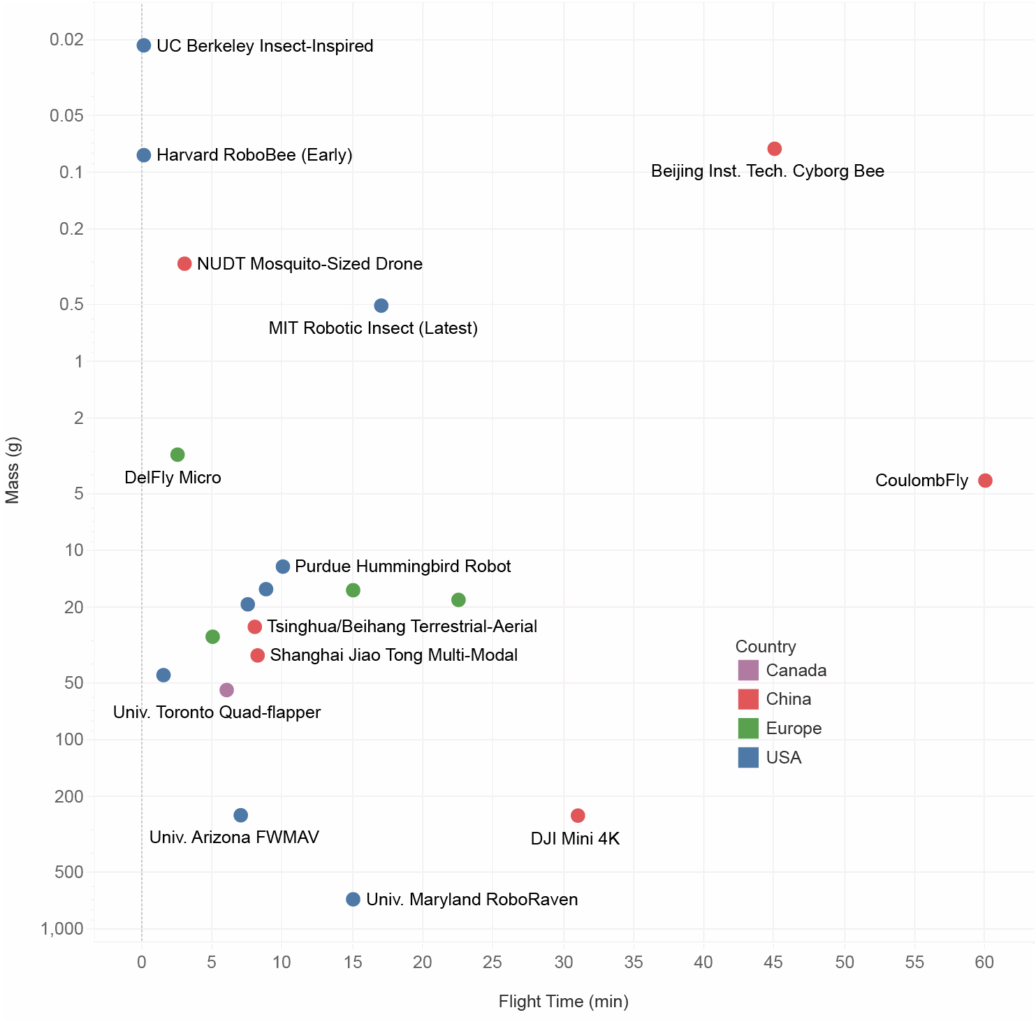
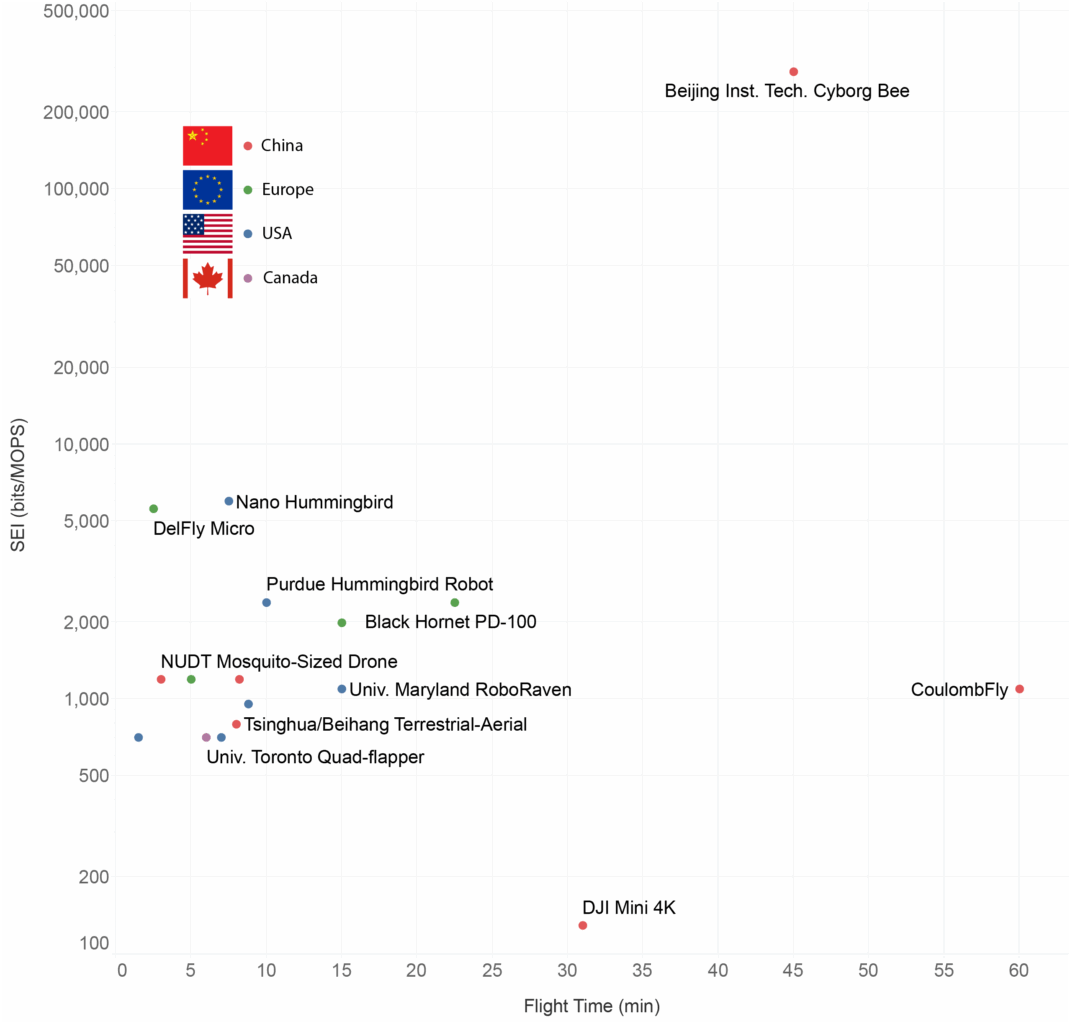
Unlike the “China has a robot Bee!” articles, I wanted to step back and survey this space and where it’s going, and, well, this is kinda a big deal. The plot below reveals the tug-of-war between a robot’s mass and its flight endurance. While a general trend shows heavier robots flying longer, the interesting data are in the extremes. Beijing’s “Cyborg Bee” is a stunning outlier, achieving incredible flight times (around 45 minutes) with a minuscule 0.074-gram control unit by cleverly outsourcing the heavy lifting to a living bee – a biological cheat code for endurance. Conversely, the “NUDT Mosquito-Sized Drone” pushes miniaturization to its absolute limit at 0.3 grams, but sacrifices practical flight time, lasting only a few minutes . This highlights the persistent “holy grail” challenge: building truly insect-scale artificial robots that can fly far–and obey orders. Even cutting-edge artificial designs like MIT’s latest robotic insect, while achieving an impressive 17 minutes of flight, still carry more mass than their biological counterparts. The plot vividly demonstrates that while human ingenuity can shrink technology to astonishing scales, nature’s efficiency in flight remains the ultimate benchmark.
Robo Bee Positioning
Researchers figured out how to deliver precise electronic pulses that create rough sensory illusions, compelling the bee to execute flight commands—turning left or right, advancing forward, or retreating on demand. And this works. During laboratory demonstrations, these bio-hybrid drones achieved a remarkable 90% command compliance rate, following directional instructions with near-perfect accuracy. By hijacking the bee’s neural pathways, China has effectively weaponized nature’s own engineering, creating a new class of biological surveillance assets that combine the stealth of living organisms with the precision of electronic control systems.
A Bee’s Brain
The Beijing team’s breakthrough lies in their precise neural hijacking methodology: three hair-width platinum-iridium micro-needles penetrate the bee’s protocerebrum, delivering charge-balanced biphasic square-wave pulses at a soothing ±20 microamperes—just above the 5-10 µA activation threshold for insect CNS axons yet safely below tissue damage limits. These engineered waveforms, typically running at 200-300 Hz to mimic natural flight central pattern generators, create directional illusions rather than forcing specific muscle commands. Each pulse lasts 100-300 microseconds, optimized to match the chronaxie of 2-4 micrometer diameter insect axons.
Figuring this out is more guessing than careful math. Researchers discovered these “magic numbers” through systematic parametric sweeps across amplitude (5-50 µA), frequency (50-400 Hz), and pulse width (50-500 µs) grids, scoring binary outcomes like “turn angle >30°” until convergence on optimal control surfaces. Modern implementations use closed-loop Bayesian optimization with onboard IMUs and nRF24L01 radios, reducing tuning time from hours to ~90 seconds while adding ±10% amplitude jitter to counteract the bee’s rapid habituation response.
You can’t figure this out on live bees. To get these measurements, the honeybee head capsule is isolated from the body while leaving the entire brain undamaged. The head is cut free and placed into a dye-loaded and cooled ringer solution in a staining chamber for 1 hour, then fixed in a recording chamber, covered with a cover-slip, and imaged under the microscope. After you do this, you can conduct experiments on hundreds of honeybees using low and high current intensity. After stimulation, the Isolated Pulse Stimulator was modulated to generate a dissociating pulse (20 µA DC, 15–20 s), which partially dissociated Fe³⁺ from the stimulating electrode and deposited it in surrounding brain tissue marking where they stimulated for post-mortem analysis.
Precise probe placement relies on decades of accumulated neuroanatomical knowledge. Researchers leverage detailed brain atlases created through electron microscopy and confocal imaging, which map neural structures down to individual synaptic connections. Before inserting stimulation electrodes, they consult these three-dimensional brain maps to target specific neural clusters with sub-millimeter accuracy. During experiments, they verify their targeting using complementary recording techniques: ultra-fine borosilicate glass microelectrodes with 70-120 MΩ tip resistance penetrate individual neurons, capturing their electrical chatter at 20,000 samples per second. These recordings reveal whether the stimulation reaches its intended targets—researchers can literally watch neurons fire in real-time as voltage spikes scroll across their screens, confirming that their three platinum-iridium needles are activating the correct protocerebral circuits. This dual approach—anatomical precision guided by brain atlases combined with live electrophysiological validation—ensures the cyborg control signals reach exactly where they need to go.
What was cool here is that they found a nearly linear relationship between the stimulus burst duration and generated torque. This stimulus-torque characteristic holds for burst durations of up to 500ms. Hierarchical Bayesian modeling revealed that linearity of the stimulus-torque characteristic was generally invariant, with individually varying slopes. This allowed them to get generality through statistical models accounting for individual differences.
Learning the signals is only half the battle. The power challenge defines the system’s ultimate constraints: while a flying bee dissipates ~200 milliwatts mechanically, the cyborg controller must operate within a ~10 mW mass-equivalent budget—about what a drop of nectar weighs. Current 3-milligram micro-LiPo cells provide only ~1 milliwatt-hour, forcing engineers toward energy harvesting solutions like piezoelectric thorax patches that scavenge 20-40 microwatts from wingbeats or thermoelectric films adding single-digit microwatts from body heat. Yes, the bee is the battery.
This power scarcity drives the next evolution: rather than imposing external commands, future systems will eavesdrop on the bee’s existing neural traffic—stretch receptors encoding wingbeat amplitude, Johnston’s organs signaling airspeed, and antennal lobe spikes classifying odors with <50ms latency at just 5 µW biological power. Event-driven neuromorphic processors like Intel’s Loihi 2 can decode these spike trains at <50 microjoules per inference, potentially enabling bidirectional brain-computer interfaces where artificial intelligence augments rather than overrides the insect’s 100-million-year-evolved sensorimotor algorithms.
Intel’s Lohi 2 Neuromorphic Chip
Challenges
Power remains the fundamental bottleneck preventing sustained cyborg control. A flying bee burns through ~200 milliwatts mechanically, but the electronic backpack must survive on a mere ~10 milliwatt mass budget—equivalent to carrying a single drop of nectar. Current micro-LiPo cells weighing 3 milligrams deliver only ~1 milliwatt-hour, barely enough for minutes of operation. Engineers have turned to the bee itself as a power source: piezoelectric patches glued to the thorax harvest 20-40 microwatts from wingbeat vibrations, while thermoelectric films capture single-digit microwatts from body heat. Combined, these provide just enough juice for duty-cycled neural recording and simple radio backscatter—but not continuous control. The thermal constraint is equally brutal: even 5 milliwatts of continuous power dissipation heats the bee’s dorsal thorax by 1°C, disrupting its olfactory navigation. This forces all onboard electronics to operate in the sub-milliwatt range, making every microjoule precious. The solution may lie in passive eavesdropping rather than active control—tapping into the bee’s existing 5-microwatt neural signals instead of imposing power-hungry external commands.
I summarize the rest of the challenges below:
Challenge
Candidate approach
Practical limits
RF antenna size
Folded‑loop 2.4 GHz BLE or sub‑GHz LoRa patterns printed on 20 µm polyimide
Needs >30 mm trace length—almost bee‑size; detunes with wing motion
Power for Tx
Ambient‑backscatter using 915 MHz carrier (reader on the ground)
100 µW budget fits; 1 kbps uplink only (ScienceDaily)
Network dynamics
Bio‑inspired swarm routing: every node rebroadcasts if SNR improves by Δ>3 dB
Scalability shown in simulation up to 5 000 nodes; real tests at NTU Singapore hit 120 roach‑bots (ScienceDaily)
Localization
Fusion of onboard IMU (20 µg) + optic‑flow + Doppler‑based ranging to readers
IMU drift acceptable for ≤30 s missions; longer tasks need visual odometry
The cyborg bee’s computational supremacy becomes stark when viewed through the lens of task efficiency rather than raw processing power. While silicon-based micro-flyers operate on ARM Cortex processors churning through 20-170 MOPS (mega-operations per second), the bee’s million-neuron brain achieves full visual navigation on just 5 MOPS—neurons firing at a leisurely 5 Hz average. This thousand-fold reduction in arithmetic operations masks a deeper truth: the bee’s sparse, event-driven neural code extracts far more navigational intelligence per computation.
To show this, I made up a metric that combines each vehicle’s vision rate, positional accuracy and onboard compute into a single “task‑efficiency” score—the Simultaneous localization and mapping (SLAM)-Efficiency Index (SEI)—so we could compare a honey‑bee brain running on microwatts with silicon drones running on megahertz. Simply put, SEI measures how many bits of world-state knowledge each platform generates per unit of processing. With SEI, the bee achieves 290,000 bits/MOPS—over 100 times better than the best silicon autopilots. Even DJI’s Mini 4K, with its 9,600 MOPS quad-core processor, manages only 420 bits/MOPS despite throwing two thousand times more compute at the problem.
This efficiency gap stems from fundamental architectural differences: bee brains process visual scenes through parallel analog channels that compress optic flow into navigation commands without digitizing every pixel, while our drones waste cycles on frame buffers and matrix multiplications. The bee’s ring-attractor neurons solve path integration as a single rotation-symmetric loop, updating its cognitive map 200 times per second (synchronized with wingbeats) using mere microwatts. Silicon systems attempting equivalent SLAM functionality—feature extraction, bundle adjustment, loop closure—burn 5-15 watts on embedded GPUs. Until neuromorphic processors can match the bee’s event-driven, power-sipping architecture, cyborg insects will remain the only sub-gram platforms capable of autonomous navigation. The chart’s below tells the story on a logarithmic scale: that lonely dot at 290,000 SEI represents not just superior engineering, but a fundamentally different computational paradigm. Note that flapping‑wing robots cluster below 200 MOPS because that’s all a 168 MHz Cortex‑M4 can supply; adding bigger processors blows the weight budget at these sizes.
The race to miniaturize autonomous flight reveals a fundamental truth about computation: raw processing power means nothing without the right architecture. While teams worldwide chase incremental improvements in battery life and chip efficiency, Beijing’s cyborg bee has leverages biology to solve this problem. Just as xAI’s Grok 4 throws trillion-parameter models at language understanding while smaller, cleaner models achieve similar results with careful data curation, bees handle similar complexity with microwatts. The lesson isn’t to abandon silicon for biology, but to recognize that sparse, event-driven architectures trump dense matrix multiplications when every microjoule counts.
Looking forward, the convergence is inevitable: neuromorphic processors like Intel’s Loihi 2 are beginning to bridge the efficiency gap, while cyborg systems like Beijing’s bee point the way toward hybrid architectures that leverage both biological and silicon strengths. The real breakthrough won’t come from making smaller batteries or faster processors—it will come from fundamentally rethinking how we encode, embed, and process information. Whether it’s Scale AI proving that better algorithms beat bigger models, or a bee’s ring-attractor neurons solving navigation with analog elegance, the message is clear: in the contest between brute force and biological intelligence, nature still holds most of the cards.
A Chinese research team just pushed quantum computing one step closer to breaking the encryption that secures your bank account. The security that protects your credit card, banking, and private messages relies on a simple mathematical bet: it would take classical computers longer than the age of the universe to crack a 2048-bit RSA key. That bet is looking increasingly risky as quantum computers inch closer to breaking the math that secures the internet.
RSA encryption is a widely used asymmetric algorithm crucial for secure digital signatures, web browsing (SSL/TLS), online banking, messaging services, VPNs, and cloud infrastructure. The web depends on RSA and, given some recent news, it’s good to take a couple minutes and get a peek at where this is going.
This month (June 2025), researchers at Shanghai University (Wang, et al) published a study in the Chinese Journal of Computers that used a D-Wave Advantage quantum annealer to factor a 22-bit RSA integer—beating the previous 19-bit record by recasting factoring as a QUBO (Quadratic Unconstrained Binary Optimization) problem. While 22 bits falls far short of the 2048-bit keys securing the internet today, it demonstrates that quantum annealers can scale beyond past limits. The researchers demonstrated that quantum annealing can turn cryptographic attacks into combinatorial optimization problems.
Headlines can be deceptive—another Chinese group “hacked” lightweight block ciphers in 2024, and a D-Wave demo factored a contrived 2048-bit semiprime whose twin primes differed by just two bits—but genuine progress is visible in the research community.
IBM Starling
Quantum annealers differ fundamentally from classical computers by utilizing quantum bits (qubits), which exploit phenomena like superposition and entanglement. This enables quantum annealers to efficiently solve certain optimization problems. Although limited in application compared to general-purpose quantum computers, quantum annealers’ recent progress highlights their potential impact on cryptographic security.
Quantum Annealer
Shor’s Algorithm
To make sense of this, I made a visualization to compare quantum annealing to Shor’s Algorithm. The “Quantum Annealer” side shows particles behaving in a fluid, probabilistic manner – they move chaotically and gradually converge toward a central point, representing how quantum annealers explore solution spaces by leveraging quantum superposition and tunneling effects to find optimal solutions through a process of gradual energy minimization. On the right, “Shor’s Algorithm” displays particles organizing into a rigid, structured grid pattern, illustrating the deterministic, step-by-step nature of classical quantum algorithms that follow precise mathematical procedures to solve specific problems like integer factorization. The contrast between the organic, exploratory movement on the quantum annealer side and the methodical, ordered arrangement on the classical algorithm side captures the essential difference between these two quantum computing paradigms: one uses quantum mechanics to probabilistically search for solutions, while the other uses quantum mechanics to execute deterministic algorithms with exponential speedup over classical computers.
Factoring large integers remains the yardstick for quantum progress because RSA’s safety rests on how brutally hard that task is for classical machines. Jumping from a 19-bit to a 22-bit crack looks tiny beside a 2,048-bit key, yet the pace signals that quantum methods—whether Shor’s algorithm or annealing—are gaining real traction.
RSA is safe for the moment, but the danger is time-shifted. Attackers can copy ciphertext today and decrypt it when hardware catches up, so any data that must stay private into the 2030s already needs stronger wrapping. Agencies and corporations are mapping every legacy backup, TLS endpoint, and VPN tunnel that still leans on RSA, then swapping certificates and firmware signatures for post-quantum or hybrid ones as they come up for renewal. The White House, NIST, and NSA’s CNSA 2.0 suite have turned that housekeeping into policy, naming lattice schemes such as CRYSTALS-Kyber, Dilithium, and SPHINCS+ as the new default. Migration is messy only for systems without “crypto agility,” the design principle that lets you change algorithms as easily as you update software.
Elliptic-curve keys used in Bitcoin and Ethereum sit even lower on the future quantum cost curve, but they, too, will fall once hardware scales. The immediate leak risk lies in records with decade-long value—medical histories, merger drafts, cold wallets, long-lived SSL certs—because those files are already being siphoned for eventual decryption.
Quantum road maps show why urgency is justified. Google’s 105-qubit Willow chip has crossed the error threshold for full fault tolerance, and IBM projects two thousand logical qubits by 2033—enough to threaten roughly 1,000-bit RSA keys.
Specifically, IBM’s roadmap targets a fault-tolerant quantum computer with 200 logical qubits by 2029 (Starling) and 2,000 by 2033 (Blue Jay). Under Shor’s algorithm, factoring an \(n\)-bit RSA key requires roughly \(2n + 2\) logical qubits , so IBM’s Blue Jay could break RSA keys up to about 999 bits by 2033. Crucially, Shor also solves discrete-log problems, meaning 256-bit ECC keys—the basis for Bitcoin’s ECDSA and Ethereum’s EdDSA—would fall with far fewer qubits, making ECC instances more vulnerable to future quantum attacks than RSA at comparable classical security levels.
Start-ups betting on photonic qubits promise faster scaling, while skeptics such as Scott Aaronson note that engineering overhead grows faster than headline qubit counts suggest. Regulators aren’t waiting: Washington demands server inventories by 2027, Brussels ties NIS2 fines to quantum-safe readiness, and Beijing is pouring billions into domestic chip fabs.
Researchers track logical-qubit lifetimes, error-corrected cycles, and real factoring benchmarks rather than raw qubit totals. A lab that links thousands of physical qubits into hundreds of long-lived logical ones would mark the tipping point where costs start resembling supercomputers, not billion-dollar prototypes.
History rarely shouts as clearly as a Chinese factoring record and a government migration order in the same quarter. It’s wise to treat post-quantum upgrades as routine maintenance—rotate keys, adopt algorithm-neutral APIs, replace certificates on schedule—and a million-qubit announcement will be just another headline. Delay, and every RSA-protected archive on your network becomes a ticking clock, counting down to disclosure day.
Communication is the most important skill to sell your ideas. If the last decade has taught us anything, it’s that ideas don’t win because they’re right—they win because someone makes them impossible to ignore. The best communicators I’ve seen combine advanced graphics with deep understanding of a subject. I start simple and show how to get started in web graphics.
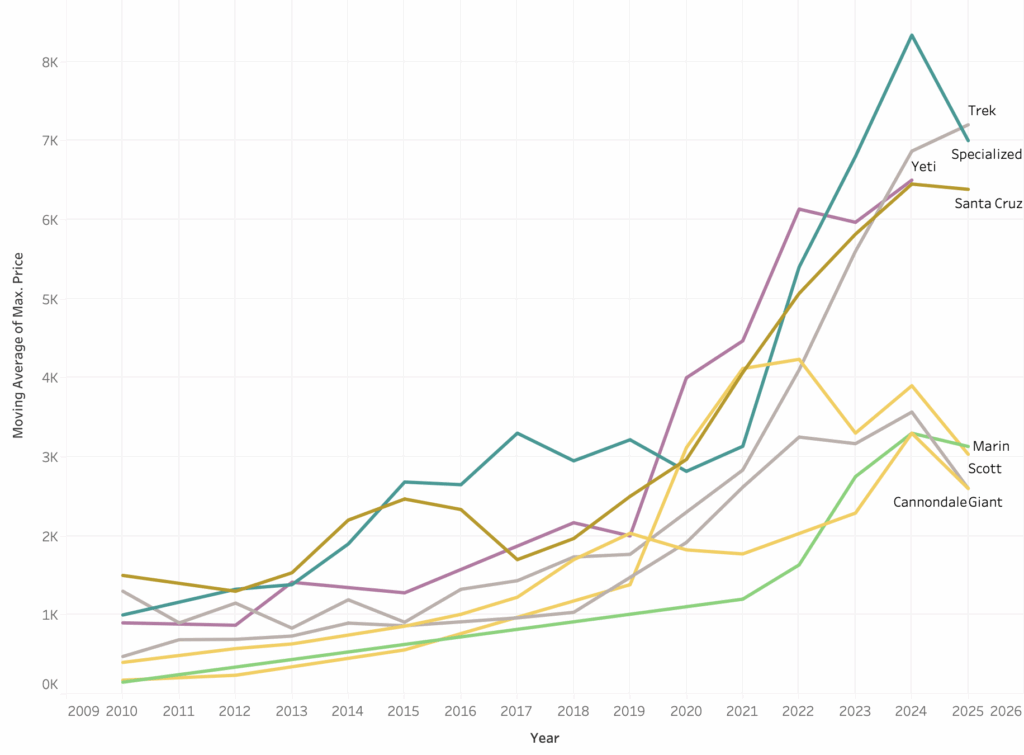
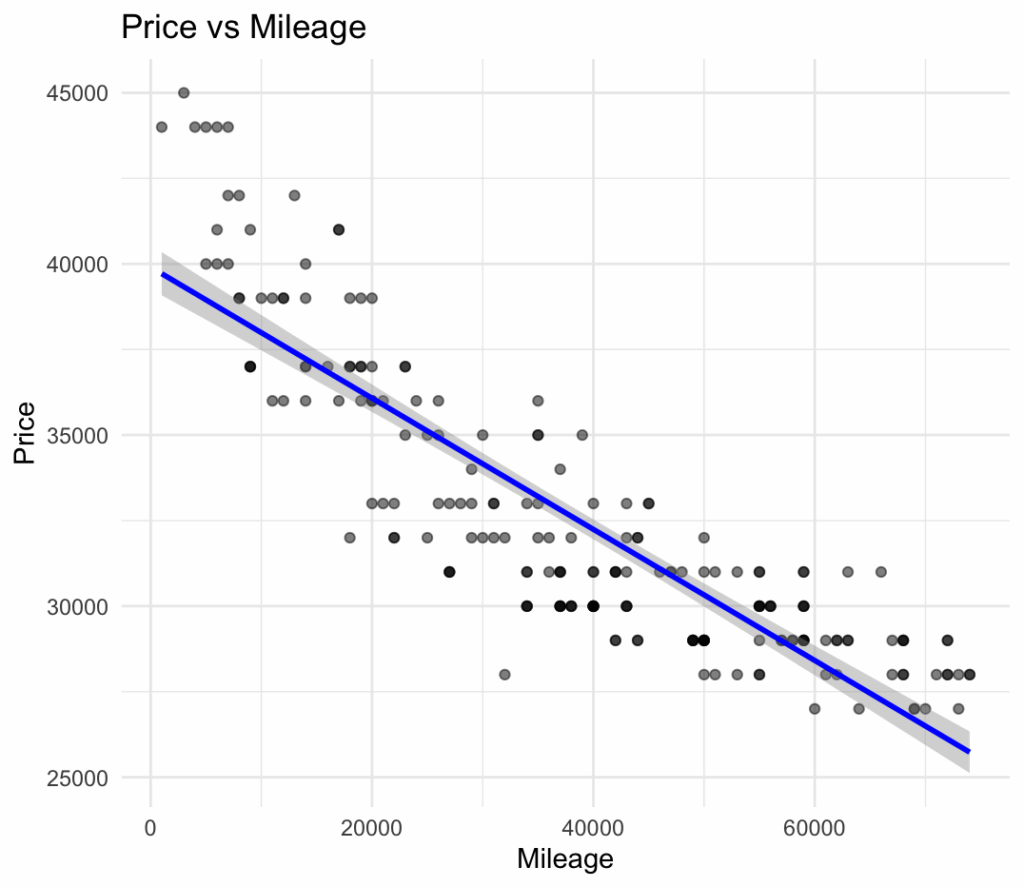
Fresh off a weekend of riding in Bentonville, I realized I need to replace my 2006 Gary Fisher Cake. But I’m data driven and love figuring out a market before I dive in. I wanted more than crowd-sourced hunches about bike pricing; I wanted numbers I could trust. New mountain bikes shed value fast—roughly 30-40 % disappears in the first year, then depreciation flattens to about 8-12 % per year until the geometry or drivetrain standard goes obsolete. Carbon frames, high-end suspension, and “halo” brands (Yeti, Santa Cruz, Pivot) hold value better than entry-level aluminum builds, yet even they nosedive if a service-heavy fork or out-of-fashion wheel size is involved. Used-bike sites quote asking prices, not what bikes actually clear for, and algorithmic estimates rarely account for regional demand or component mix. So I scraped Craigslist, Facebook Marketplace, and Bicycle Blue Book, built my own price model, and now shop with a spreadsheet instead of wishful thinking—seeing at a glance whether that $2,400 Fuel EX is a bargain.
Getting the Data
To build this bike listings dataset, I used a combination of scraping tools and manual extraction strategies across three major platforms: Craigslist, Facebook Marketplace, and Bicycle Blue Book.
For Craigslist, I automated the process end-to-end. I wrote a script (download_cl_raw.py) to fetch city-specific HTML pages using a custom User-Agent and parsed embedded JSON-LD blocks to extract listing data (which you can see here). This raw data was then processed by analyze_and_load_cl.py, which parses structured fields (e.g., brand, model, year, frame material) using regexes and known brand patterns. Only well-known mountain bike brands were retained to ensure data quality.
Facebook Marketplace posed more challenges due to limited APIs and anti-bot measures. To work around this, I manually saved listing pages via the Chrome Developer Tools (see my data here), then used BeautifulSoup (facebook_parser.py) to extract the price, location, and other specs from the HTML. Brand and model parsing reused similar regex-based logic.
For Bicycle Blue Book, I also manually downloaded the listing HTML (data here) and used a script (bb_extractor.py) to extract structured rows like name, type, size, and price using CSS selectors.
Finally, all listings were normalized, cleaned (e.g., prices cast from “$2,800” strings to numeric), and inserted into a fresh PostgreSQL table (bike_listings_new) using upload_bikes.py.
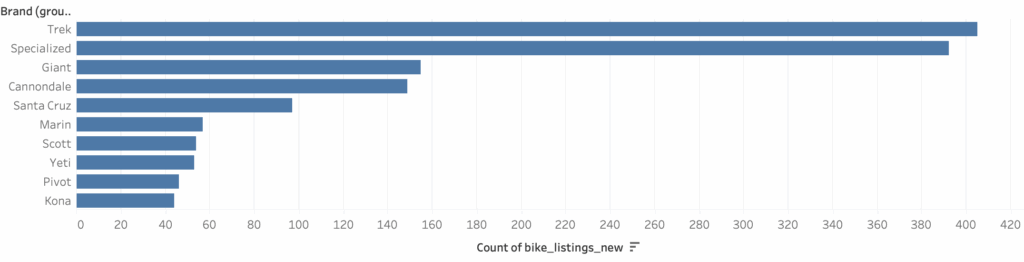
This multi-pronged approach resulted in 1,861 listings with high coverage of core fields like brand, model, year, and price, though fields like frame_size and suspension remain sparsely populated. The dataset now supports robust price modeling, brand comparisons, and cross-market analysis.
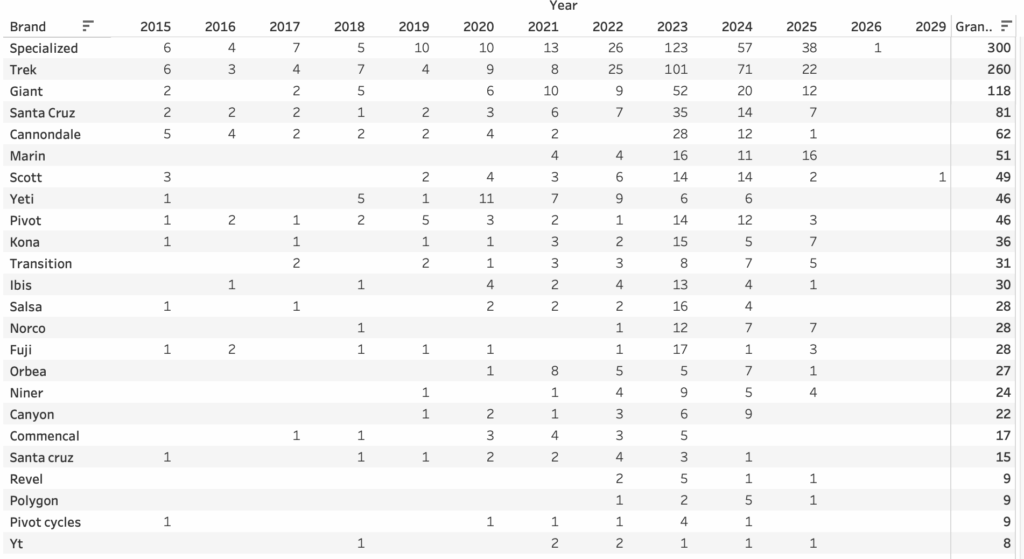
Brand Count (n > 42)
The most represented brands are Specialized (300 bikes), Trek (260), and Giant (118), with most listings concentrated in recent years like 2023 and 2024. Specialized alone accounts for over 100 bikes listed in 2023, showing clear popularity and availability on the secondhand market. Model year coverage spans from 2015 to 2025, with the majority of data coming from the last five years. In terms of data completeness, core fields like title, price, brand, and year are over 95% populated, while others such as frame_size, wheel_size, and drivetrain have much sparser coverage. Notably, only 20% of entries have frame_size and less than 10% have detailed mechanical specs like brake_type or suspension. This makes broad comparisons possible on price and brand, but highlights the challenges in making deeper component-level comparisons—especially since components and condition may vary significantly even within the same model and year. Nonetheless, the dataset offers a strong foundation for analyzing used bike market trends, pricing gaps between platforms, and brand popularity over time.
Some parameters I could get 100% coverage, while there was nearly no data on tires or suspension travel. You should check out this monster query to generate this table.
column_name
populated_count
missing_count
total_rows
percentage populated
id
1861
0
1861
100
city
1861
0
1861
100
post_date
1861
0
1861
100
price
1861
0
1861
100
currency
1861
0
1861
100
title
1861
0
1861
100
brand
1861
0
1861
100
scraped_at
1861
0
1861
100
source
1861
0
1861
100
model
1854
7
1861
99.62
year
1794
67
1861
96.4
frame_material
1735
126
1861
93.23
original_model
1682
179
1861
90.38
location
1679
182
1861
90.22
frame_size
378
1483
1861
20.31
url
237
1624
1861
12.74
wheel_size
173
1688
1861
9.3
drivetrain
95
1766
1861
5.1
brake_type
47
1814
1861
2.53
suspension
12
1849
1861
0.64
tire_brand
2
1859
1861
0.11
travel
1
1860
1861
0.05
Bike Count by Brand and Year
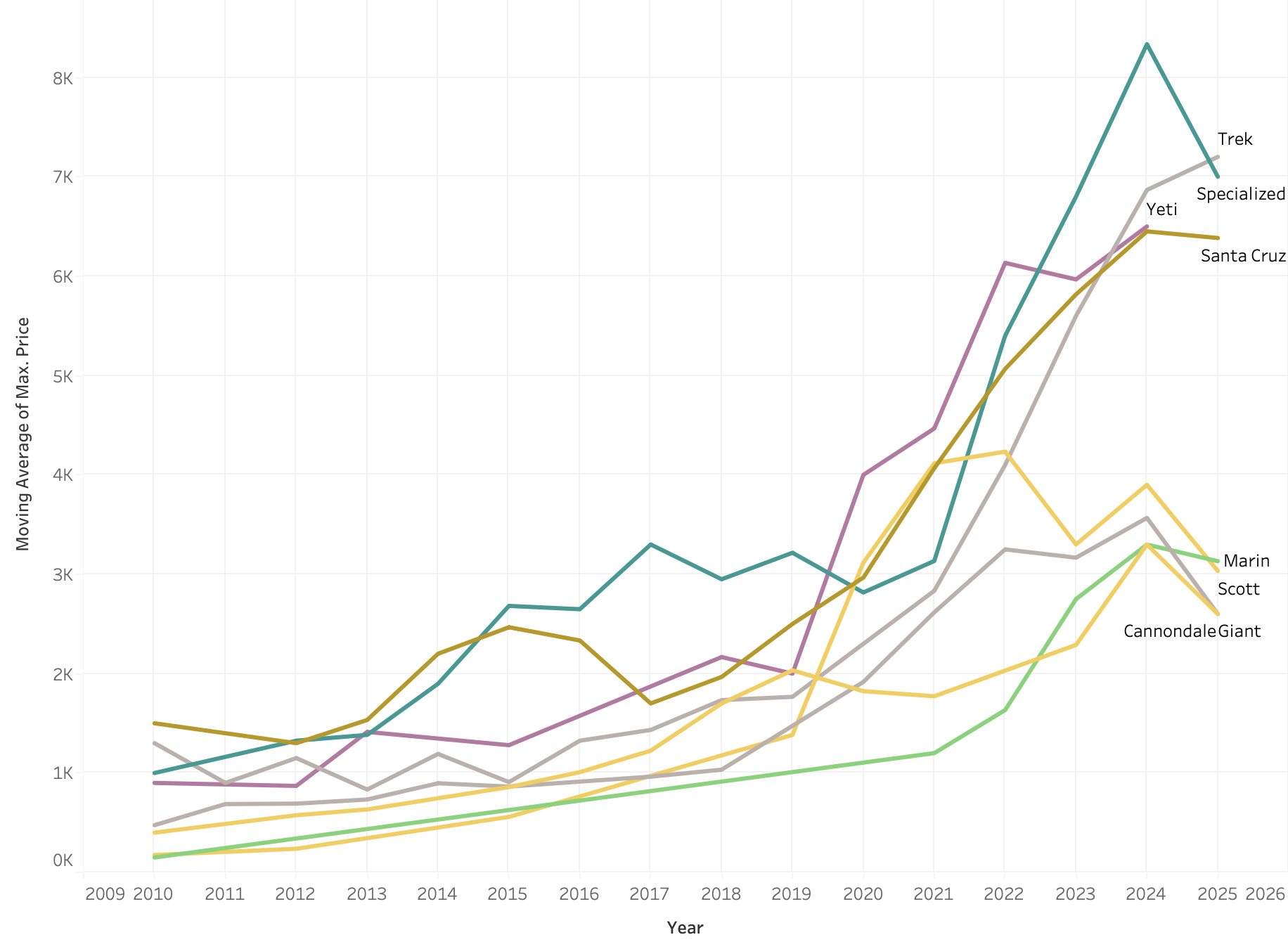
Max of price each year by brand
Initial Observations
My first question, was how prices compare between facebook, craiglist and bicycle bluebook. Craigslist prices are systematically lower—often by 20–50%, and sometimes by multiples—for the same year+model. eg. in 2019 Switchblade: CL $1,500 vs FB $2,000 and SB150: CL $3,300 vs FB $3,600. BicycleBluebook, when present, sits between Craigslist and Facebook, acting as a mid-market reference. This supercool sql let me compare the sites.
year
model
avg craigslist
avg facebook
avg bb
abs spread
max_min ratio
2024
Marlin 6
$2,800.00
$500.00
$2,300.00
5.6
2024
Stumpjumper
$1,026.25
$2,375.00
$1,348.75
2.31
2023
Tallboy
$1,150.00
$2,600.00
$1,450.00
2.26
2023
Stumpjumper
$1,085.00
$2,371.67
$1,286.67
2.19
2024
Fuel EX 8
$1,108.33
$2,300.00
$1,191.67
2.08
2024
141
$3,500.00
$1,900.00
$1,600.00
1.84
2021
SB95
$1,500.00
$2,500.00
$1,000.00
1.67
2021
SB150
$2,000.00
$3,200.00
$1,200.00
1.6
2022
Trance X 3
$1,200.00
$1,900.00
$700.00
1.58
2023
Fuel EX 5
$856.25
$1,350.00
$493.75
1.58
2022
Spark 960
$1,849.00
$1,200.00
$649.00
1.54
When comparing average bike prices across Craigslist, Facebook, and BicycleBluebook for the same year and model, there are striking disparities. Similar spreads are evident for popular models like the Stumpjumper and Tallboy, where Facebook listings consistently command significantly higher prices. In other cases, such as the Fuel EX 8 and SB150, the Craigslist price is notably lower by over $1,000 on average. While these differences are compelling, it’s important to note that they may reflect variations in bike condition, component specs, and seller expectations rather than pure market inefficiency. Still, the consistent patterns suggest that Craigslist may offer lower-priced listings on average, while Facebook often reflects a more premium price tier.
Does the city matter?
(no, cuz this market is crazy)
From some quick analysis, most brand-model-year combinations appear in only one city, so their local average simply is the national average (100 % rows). There is just not enough clean data to answer this question and the one conclusion I take away is that bike pricing is a super inefficient market. Where a combo shows up in two markets the price gaps are striking: a 2025 “unknown” Specialized lists for $750 on Seattle’s boards— about 50 % above the national mean—while the same mystery build averages only $240 in Chicago (≈ 50 % below). Likewise, 2023 Trek “unknowns” fetch $1,348 in Denver (151 % of national) but just $433 in Los Angeles (49 %). Even with tiny sample sizes (3–5 bikes each), the pattern suggests regional demand and seller optimism can swing asking prices for identical vintage-and-brand bikes by a factor of two or more.
A more sophisticated check backs this up. Only one usable “city” dummy survived the frequency filter, and LightGBM never bothered to split on it—its total gain and split count are both zero. When we rebuilt the model with the city column entirely removed, the median-absolute-error stayed exactly the same ($1,082). In short, regional location adds no predictive power in this data; age, brand, and frame material explain nearly all of the price variation we can capture, while the city a bike is listed in appears irrelevant.
Model
I built a model to sift through thousands of real listings—accounting for brand reputation, frame material, the bike’s age, and even how prices vary from city to city—to predict a fair, middle-of-the-road price in seconds. Think of it as my own personal Kelley Blue Book for bikes.
Under the hood, the valuation engine marries a classic machine-learning preprocessing stack with a modern gradient-boosted quantile regressor. Continuous bike attributes (age, log-age) sail through a median-imputer, while brand, frame material, size, and city are one-hot–encoded with frequency pruning so the feature matrix stays lean even as new makes appear. I trained with GroupKFold keyed on city—crucial for second-hand markets where geography drives pricing—to guarantee our test fold is a truly out-of-town set. A ridge model gives a transparent linear baseline, but the production scorer is a LightGBM quantile model at \(\alpha = 0.5\), which directly learns the market median. Boosting captures the steep price cliffs between prestige brands and commodity frames, while quantile loss hedges against outliers that plague classifieds. The result is a file-light pipeline (preprocessor + model serialized at ~ MBs) that returns instant, geographically realistic price medians—ideal for auto-pricing listings, negotiating buys, or flagging bargains the moment they’re scraped.
You can see all the code and results here at my google colab.
Top features by total gain: feature score 4 cat__frame_material_Aluminum 83.397947 0 num__age 40.415536 3 cat__brand_infrequent_sklearn 29.515867 5 cat__frame_material_Carbon 15.131043 1 num__log_age 8.443574 2 cat__brand_Santa Cruz 5.624613 6 cat__frame_size_missing 0.000000 7 cat__city_Fort Worth 0.000000
The LightGBM model’s own score-gain metrics say the single most powerful signal in predicting a used-bike’s median price is simply whether the frame is aluminum (gain ≈ 83). In other words, the algorithm most often chooses to split first on “Aluminum vs. everything else,” because that decision alone lops the most error off its price guesses. Classic depreciation comes next: the bike’s age in years carries roughly half as much influence (gain ≈ 40), confirming that time on the trail is the second-biggest driver of resale value. A close third is an umbrella flag for infrequent or boutique brands—if a listing’s brand falls outside the mainstream, the model adjusts sharply (gain ≈ 30). Carbon frames still matter but noticeably less than aluminum/other (gain ≈ 15), and finally the log-age term (gain ≈ 8) offers the model a gentle curve to fine-tune how price drops level off as bikes get very old. Funny to see the Santa Cruz brand effect too.
Net takeaway: material and time dominate; brand prestige matters mainly at the extremes, and once the model knows those things, everything else is icing.
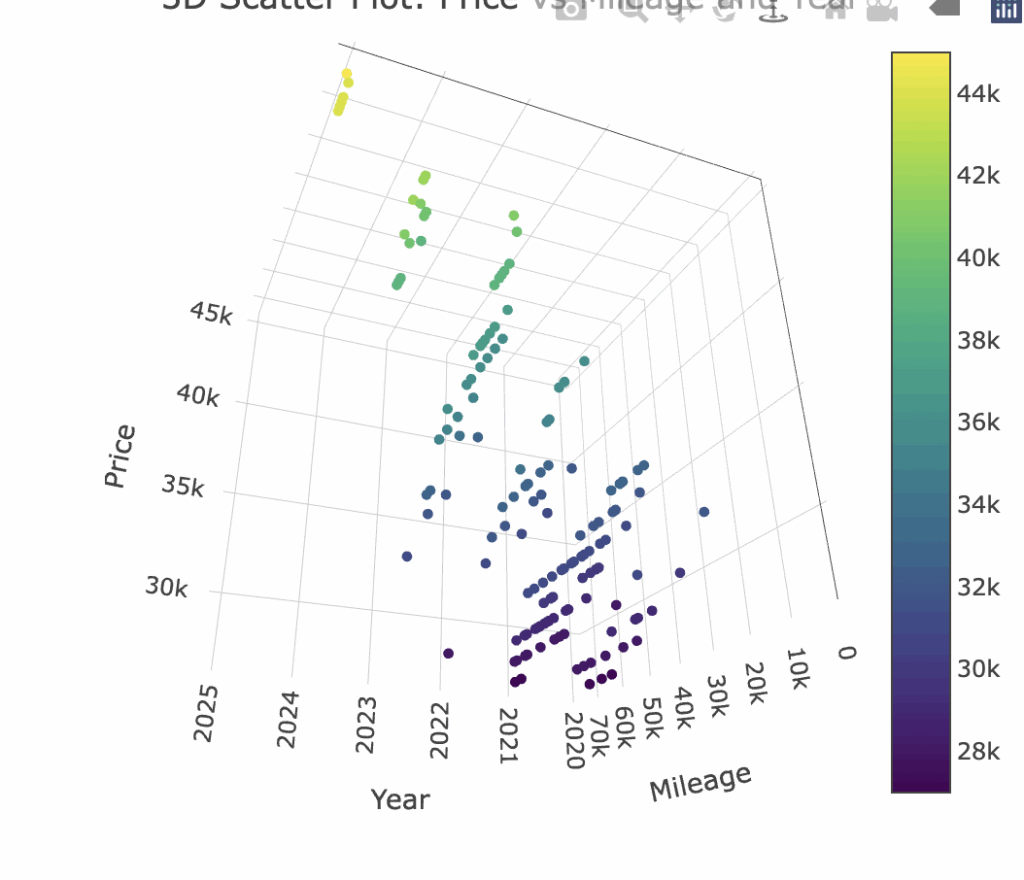
In today’s crowded used‐EV market, it can be nearly impossible to sift through hundreds of messy web pages and figure out what really drives a Tesla Model Y’s price. That’s why I’m taking a data‐first approach: we’ll pull the full listing text for 250 Long Range Model Ys from CarMax (despite their tangled HTML), clean and organize it into a Google Sheet, then feed it into R. With just a few lines of R code we’ll plot price against both model year and odometer reading, fit a simple linear regression, and package it into an easy-to-use price-estimator function. Finally, we’ll repeat the process on Carvana data and compare the two—to reveal exactly how much “newness” vs. “mileage” each dealer rewards, and help you pinpoint the ideal Year/Mileage combination so you can drive away in your sweetest Model Y deal without ever overpaying.
To do this, I pull up https://www.carmax.com/cars/tesla/model-y/long-range?showreservedcars=false. The html is super messy, but you can display everything with a couple clicks, select all and copy and give the text on 250 cars to chatgpt to make a nice table in google sheets. (Something I used to write a lot of code and headless browsing to do. Now just copy and paste the mess into an LLM.)
Then with this r script, I could build a little model:
How much does age affect price (about $2000/yr)
And how much does mileage affect price? (every additional mile reduces the predicted price by about 9 cents)
We can make a model that looks at both variables and a linear model fits pretty well.
summary(model)
Call: lm(formula = Price ~ Year + Mileage, data = df)
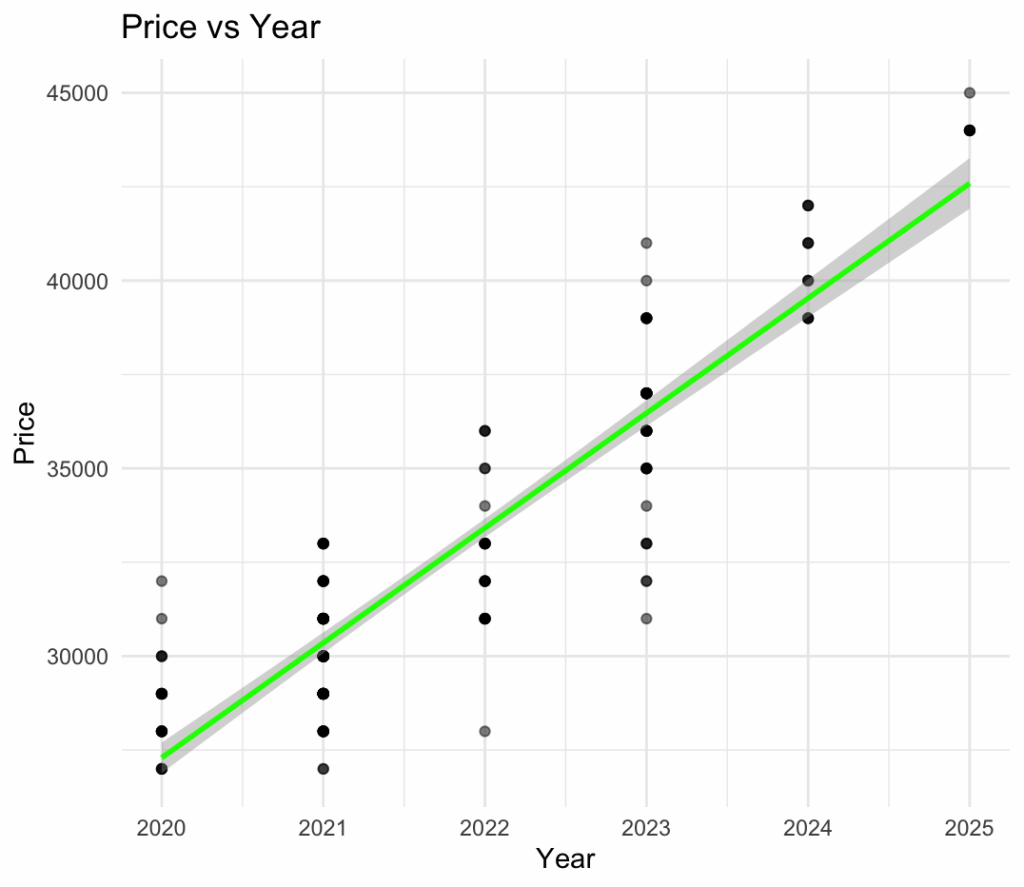
Residuals: Min 1Q Median 3Q Max -3726.0 -857.4 86.9 801.9 2871.1
The linear model predicting Tesla Model Y prices based on Year and Mileage shows a very strong fit to the data. The multiple R-squared value is 0.9092, indicating that approximately 91% of the variation in Price is explained by the two predictors. Both Year and Mileage are highly statistically significant (p-values < 2e-16), confirming that newer vehicles and lower mileage are strong predictors of higher prices. The coefficient for Year is approximately $1,986, meaning each additional year (newer) increases the predicted price by about $2,000, holding mileage constant. Conversely, the coefficient for Mileage is approximately -9 cents per mile, meaning every additional mile reduces the predicted price by about 9 cents. The residual standard error is $1,287, suggesting that the typical prediction error is around $1,300, which is relatively small compared to the average vehicle price in the dataset. Overall, the model demonstrates excellent explanatory power and precision for this pricing prediction task.
So then it’s easy to build a function to check if the price is right:
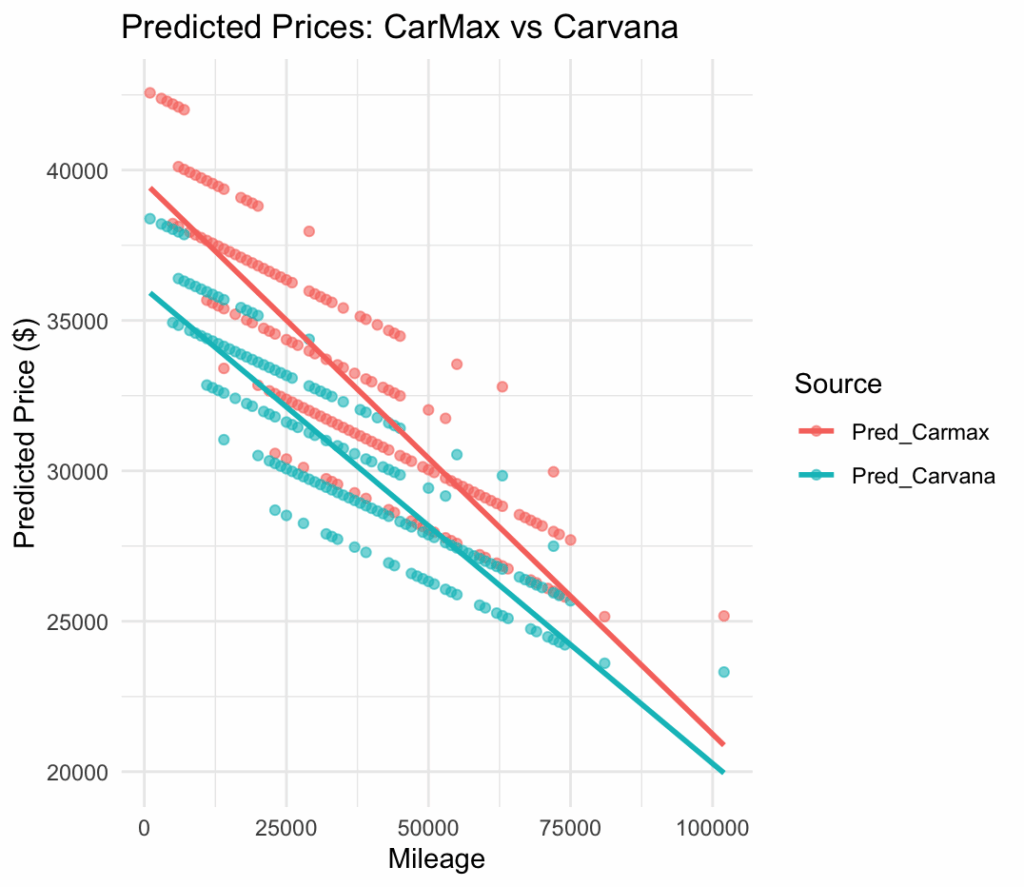
We can then build a model to compare carvana and carmax by doing the same thing to Carvana’s web page:
[1] "Model Coefficient Comparison:" Term Carmax Carvana Difference (Intercept) (Intercept) -3.979085e+06 -3.103468e+06 -8.756172e+05 Year Year 1.986047e+03 1.551575e+03 4.344724e+02 Mileage Mileage -9.352694e-02 -8.777679e-02 -5.750151e-03 `geom_smooth()` using formula = 'y ~ x'
When comparing the pricing models between CarMax and Carvana for used Tesla Model Y vehicles, some notable differences emerge. Both models fit a simple linear regression of Price ~ Year + Mileage, but their coefficients tell an interesting story. CarMax vehicles show a slightly higher sensitivity to the vehicle’s year, with a coefficient of $1,986 per year compared to Carvana’s $1,552 — meaning newer cars retain more value at CarMax. Meanwhile, the mileage penalty (the amount price drops per additional mile) is steeper at CarMax, at about 9.35 cents per mile, compared to 8.78 cents at Carvana. Overall, CarMax’s prices tend to start lower. This suggests that CarMax is pricing aggressively lower on older, higher-mileage vehicles, while Carvana offers slightly higher baseline prices but discounts mileage more gently. These differences could reflect strategic positioning: CarMax competing more on price, Carvana offering a convenience premium.
If we anchor both models at a typical vehicle—say a 2022 Model Y with 49 000 miles, this is all pretty clear:
So on an average 2022, 49,000 mi car, CarMax’s model actually prices it about $2,600 higher than Carvana’s. In practical terms, CarMax seems to lean on year more heavily—charging a steeper premium for newer cars—while also carving off more per mile of wear. Carvana, by contrast, starts a little higher (gentler intercept) but discounts mileage more slowly, resulting in lower predicted prices on higher‐mileage examples. This aligns with CarMax’s more aggressive price‐based positioning on older, higher‐use vehicles and Carvana’s strategy of a slightly higher baseline with more gradual mileage adjustments.
So now we have an estimate_price(2024, 20000) function which tells us: 38803.62
So what should I buy if I’m looking for the sweet spot between value, battery health, and “new‐feel,” my models suggest targeting roughly a 2021–2022 Model Y with 20 000–30 000 miles on the odometer. Here’s why:
Battery life: Tesla batteries typically lose around 2–3% capacity per year plus 2% per 10 k miles. A 2022 car with ~30 k miles will still have around 90–93% of original capacity—plenty of range for daily driving and road trips.
Price:
CarMax predicts about $34 000 for a 2022/30 k example,
Carvana predicts about $32 000—so you’re looking at $32–34 k in that neighborhood.
Value boost: Jumping up to 2023 shaves less than $1000 off mileage penalties but adds $1500–2000 on the year premium; dropping down to high‐mileage 2020s saves only ~$3000 but costs you 15–20% battery health.
Bottom line: A 2021–2022 Tesla Model Y with 20,000–30,000 mi strikes the best balance—excellent battery life (≥90%), newer features, and a sweet spot in the $32–34 krange. If you can stretch to 2022 and keep mileage under 25k, you’ll maximize both range and resale value without overpaying.
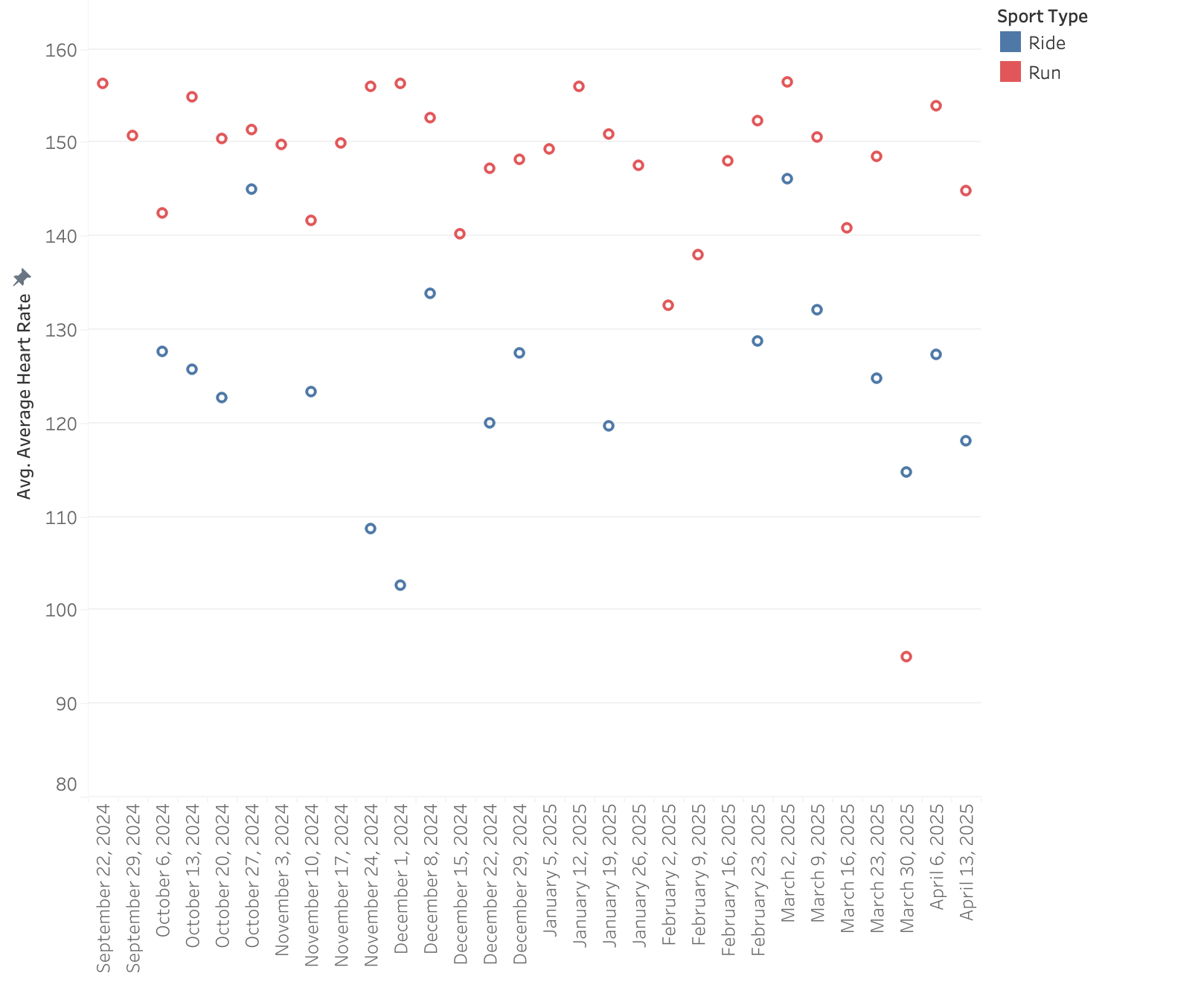
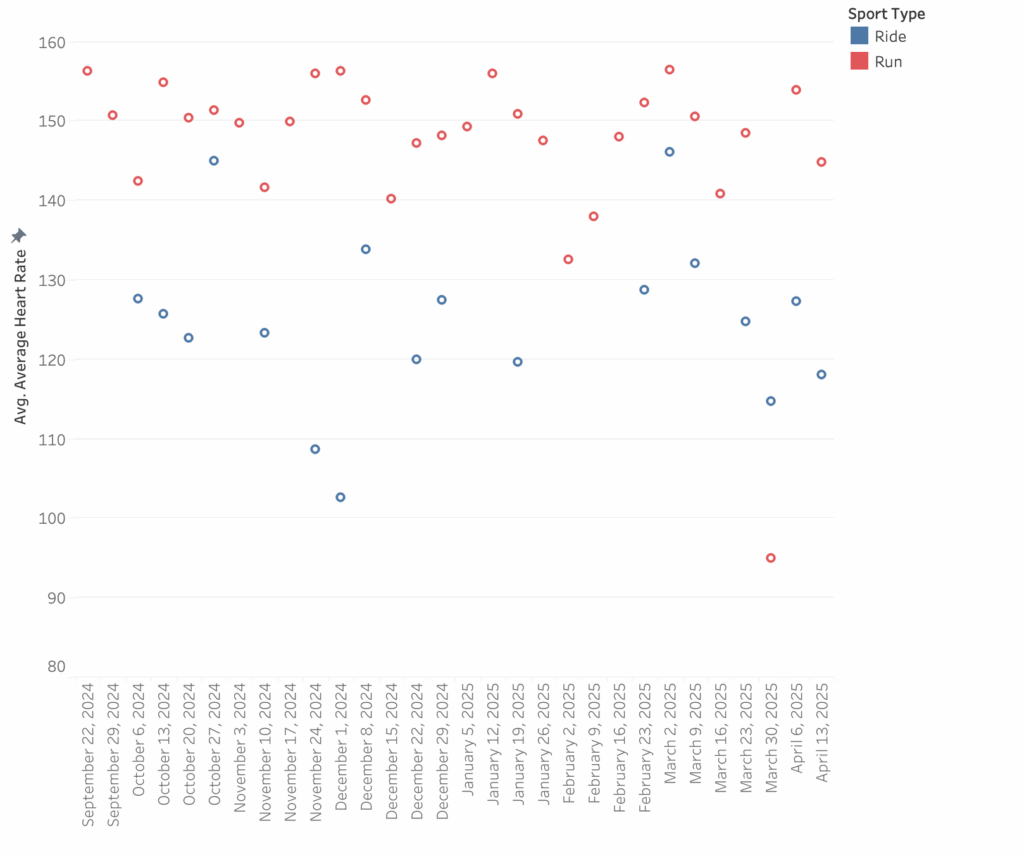
I can’t get my heart rate up on the bike, even when I feel I’m pushing hard. I grind up hills, spin through flats, and yet it’s hard to get above 120–130 bpm. I run at 160 bpm and race at 170-180.
Cycling is a very muscle‑specific sport. Unlike running, where your whole body (and the impact forces) drive your cardiovascular response, cycling isolates the work to your legs. If your leg muscles—particularly your quads, glutes, and hamstrings—aren’t strong enough to generate high power, you’ll fatigue locally before your heart and lungs get taxed. In other words, your legs give out before your cardiovascular system even gets a chance to climb to higher zones.
The chart shows my average HR on bikes (blue) and runs (red). It’s not completely dominant, but the trend is clear. When I run, my heart rate easily climbs into the 170s, but when I’m biking—even pushing hard—I struggle to get above 110 bpm. I looked into this a bit and it’s a well-documented physiological difference between running and cycling, rooted in both biomechanics and cardiovascular dynamics.
Running is a full-body, weight-bearing activity that recruits a large number of muscle groups: not just the legs, but also the core and upper body for stabilization. That broad muscle recruitment demands more oxygen, more energy, and therefore a higher cardiac output. My heart needs to pump faster and harder to meet that demand, especially when I’m running uphill or accelerating. In contrast, cycling primarily engages the lower body—quads, glutes, hamstrings—and even though those muscles are working, the overall systemic demand is lower.
Then there’s body position. On a bike, I’m seated, often with my torso leaning forward. This posture actually helps venous return—the process of blood returning to the heart—by reducing gravitational resistance. With improved preload, the heart can eject more blood per beat (higher stroke volume), so it doesn’t need to beat as frequently to achieve the same cardiac output. The net result: lower heart rate for the same level of oxygen delivery.
Cycling is also non-weight-bearing. There’s no impact, no ground reaction force, and no constant stabilization with every stride. That reduces overall neuromuscular and cardiovascular load. The metabolic cost of supporting body weight is significantly lower on the bike, which means less activation of the sympathetic nervous system, less catecholamine release (like epinephrine and norepinephrine), and therefore a lower heart rate response.
There’s also something to be said for specificity and conditioning. I’ve trained myself to run hard. My body is used to ramping up HR and oxygen delivery for running efforts. But biking is a different motor pattern, and if I haven’t trained those muscles or systems to handle high-load aerobic work on the bike, the heart rate won’t respond the same way. Even if it feels hard—because my legs are burning from lactate buildup or local muscular fatigue—that doesn’t mean the cardiovascular system is stressed enough to elevate heart rate.
Finally, effort on the bike can be deceptive. I have a power meter and I can keep that up around 200W, but I really want to get to 250 on average. But unlike running, where ground contact and muscle engagement are rhythmic and consistent, cycling effort can be variable and harder to quantify.
So when I’m on the bike and can’t get my heart rate up, it’s not that I’m not working. It’s that the cardiovascular, positional, and neuromuscular dynamics of cycling fundamentally produce a lower heart rate for a given perceived effort. Understanding that helps me train smarter—and recognize that heart rate alone isn’t the full story.
How do I fix this?
I have to boost leg power.
Here’s how I’m thinking about tackling this problem. The issue isn’t just cardiovascular—it’s neuromuscular. My body simply isn’t trained to fire the right motor units efficiently on the bike. Running is second nature by now, but biking demands different recruitment patterns and muscle coordination, especially from muscles like the glutes and vastus lateralis. If the neuromuscular system isn’t trained, I won’t be able to sustain the output needed to drive my heart rate up, regardless of how hard I feel like I’m working.
The second factor is muscular endurance. If my legs tire early, they become the limiter before the heart even gets close to max output. That’s a clear sign I need both more time in the saddle and targeted strength work. The science here is pretty strong: exercises like leg press, lunges, and single-leg squats directly build the muscle groups responsible for power on the bike. They also improve neuromuscular coordination, increase muscle fiber recruitment, and raise fatigue resistance.
From a ride programming perspective, I need to develop the ability to push higher cadences under moderate resistance—specifically 1–2 minute spin-ups at 100–110 RPM. This builds speed and muscle efficiency at higher outputs without requiring massive torque. Over time, it can help train the neuromuscular connection to sustain higher intensities at lower perceived effort.
I’ll also lean hard into hill repeats—4 to 6 sets of 3-minute climbs with full recovery. This kind of session pushes VO2 max systems and helps develop lactate tolerance. It’s the cycling equivalent of running strides uphill. Those 3-minute intervals are long enough to tax both aerobic and anaerobic systems and short enough to allow full engagement without form breakdown. And it’s repeatable, so I can track progress.
But the foundation is really about hitting all energy systems: tempo, threshold, and VO2. I’m planning to ride three times a week: one session focused on tempo or threshold with 8–20 minute intervals; one session focused on VO2 with 2–4 minute intervals; and one longer aerobic ride to build endurance and efficiency. That progression covers the full spectrum of adaptation—from mitochondrial density to lactate clearance to neuromuscular economy.
As for gear, I love my setup right now. My bike felt great today, and honestly, a $30 computer is giving me everything I need at this stage. I’m not yet fit enough to fully benefit from better equipment. The marginal gains would be there, sure—but the main limiter is still my body, not the bike. Fitness comes first.
And on tools—Apple Watch does estimate VO2 max, though it’s more accurate for running than cycling unless paired with a power meter and heart rate strap which are on ant+. But ultimately, the real measure will be how I feel on the bike and whether I can start getting that heart rate up into higher zones consistently. That’s the goal—and this plan gives me a roadmap to get there.
(warning: I’m not trying here to explain something to folks outside computer science, but more summarize something awesome I’m learning that is changing how I write code)
As software systems grow increasingly complex and automated, ensuring correctness becomes a monumental challenge. In a future of automatically generated code, certainty is both elusive and critical. Enter Lean, a modern interactive theorem prover designed to help you reason rigorously about your code, verify its correctness, and even prove mathematical theorems. A long term research thread of mine is to make these tools increasingly useful with the goal of building stuff faster while dramatically increasing security.
Lean is a functional programming language and interactive theorem prover created by Leonardo de Moura at Microsoft Research in 2013, now an open-source project hosted on GitHub. It facilitates writing correct and maintainable code by focusing on types and functions, enabling users to concentrate on problem-solving rather than implementation details. Lean boasts features such as type inference, first-class functions, dependent types, pattern matching, extensible syntax, hygienic macros, type classes, metaprogramming, and multithreading. It also allows verification by proving properties about functions within the language itself. Lean 4 is the latest version, supported by the active Lean community and the extensive mathematical library Mathlib. Additionally, the Lean FRO nonprofit was founded in 2023 to enhance Lean’s scalability, usability, and proof automation capabilities.
Lean is a formal proof assistant—a tool that allows you to write mathematical proofs or verify software formally. It merges powerful logical foundations with ease of use, making formal verification more approachable than ever before. It’s fully integrated with visual studio.
This matters because formal verification with Lean significantly improves software reliability, reducing bugs and enhancing safety in critical sectors such as aerospace, finance, and healthcare. Lean’s rigorous approach provides exceptional precision, enabling detection of subtle errors that traditional testing often overlooks. Additionally, Lean offers profound mathematical insights, empowering mathematicians to formally confirm intricate proofs common in advanced mathematics. If fully understanding the logic of advanced math isn’t the most powerful application of AI, I don’t know what is.
The Hello.lean file serves as the root module, importing Hello.Basic:
import Hello.Basic
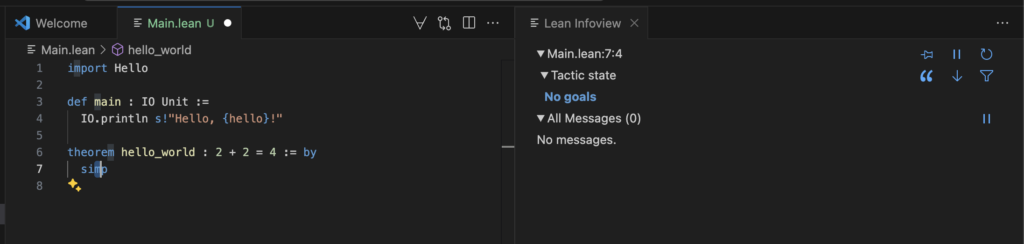
The Main.lean file combines these elements and includes a formal proof:
import Hello
def main : IO Unit :=
IO.println s!"Hello, {hello}!"
theorem hello_world : 2 + 2 = 4 := by
simp
Here, the main function prints a greeting, while the hello_world theorem demonstrates Lean’s capability to formally verify that 2 + 2 equals 4 using the simp tactic.
In Lean 4, the simp tactic is a powerful tool used to simplify goals and hypotheses by applying a collection of simplification lemmas, known as simp lemmas. These lemmas are tagged with the @[simp] attribute and are designed to rewrite expressions into simpler or more canonical forms. When invoked, simp traverses the goal or hypothesis, applying applicable simp lemmas to transform the expression step by step. For example, in proving the theorem 2 + 2 = 4, the simp tactic automatically simplifies the left-hand side to match the right-hand side, effectively completing the proof without manual intervention. This automation makes simp an essential tactic for streamlining proofs and reducing boilerplate in formal verification.
“No goals” mean the proof completes
By running lake build, Lean compiles the project and verifies the theorem. If the theorem is incorrect or the proof is invalid, Lean will provide an error, ensuring that only mathematically sound code is accepted.
This approach to software development, where code correctness is mathematically guaranteed, is especially valuable in critical systems where reliability is non-negotiable. Lean 4 empowers developers to write code that is not only functional but also formally verified, bridging the gap between programming and mathematical proof.
At this point, you are probably wondering, what Lean can really do. Every human knows 2 + 2 = 4. So let’s do something real with a real proof by induction.
-- a more interesting proof: ∀ a b, a + b = b + a
theorem add_comm (a b : Nat) : a + b = b + a := by
induction a with
| zero =>
-- 0 + b = b + 0 reduces to b = b
simp
| succ a ih =>
-- (a+1) + b = (b + a) + 1 by IH, then simp finishes
simp [ih]
In this example, Lean isn’t merely checking a single arithmetic equation; it’s proving that addition on the natural numbers is commutative in full generality. By invoking the induction tactic on \(a\), Lean first establishes the base case where \(a = 0\)—showing \( + b = b + 0\) reduces to the trivial identity \(b = b\)—and then handles the inductive step, assuming \(a + b = b + a\) to prove \((a + 1) + b = b + (a + 1)\). In each case, the simp tactic automatically applies the appropriate lemmas about Nat addition to simplify both sides of the equation to the same form. Finally, when you run lake build, Lean silently compiles your code and verifies both the simple fact \(2 + 2 = 4\) and the full commutativity theorem; if any part of the proof were flawed, the build would fail, ensuring that only completely correct mathematics makes it into your code.
You can continue this to prove other properties of math.
import Hello
def main : IO Unit := do
IO.println s!"Hello, {hello}!"
IO.println "All proofs have been verified by Lean!"
-- trivial fact: definitionally true
theorem hello_world : 2 + 2 = 4 := by
rfl
-- use core lemmas directly
theorem add_comm (a b : Nat) : a + b = b + a := by
exact Nat.add_comm a b
theorem mul_add (a b c : Nat) : a * (b + c) = a * b + a * c := by
exact Nat.mul_add a b c
For the more substantial theorems, we use the exact tactic to invoke core library lemmas directly: Nat.add_comm proves commutativity of addition \((a + b = b + a)\), and Nat.mul_add proves distributivity of multiplication over addition \((a * (b + c) = a * b + a * c)\). By relying on these already‑proven lemmas, Lean’s compiler verifies each theorem at build time—any failure in these proofs will cause lake build to error out.
Ok, so proving the basic properties of math is super cool, but how exactly is this useful? Below is an example of a “real‑world” optimization—rewriting a naive, non‑tail‑recursive summation over a list into a tail‑recursive loop—and formally verifying that the optimized version is equivalent to the original. This kind of proof is exactly what you’d need to trust that your performance tweaks haven’t changed the meaning of your code.
In embedded systems, optimization matters. The code below demonstrates how Lean can formally verify that a tail-recursive optimization is functionally equivalent to its naive counterpart—a task that’s often error-prone when done manually in traditional languages like C. The function sum is a simple, natural recursive definition that adds up all the elements of a list. It’s clear and expressive but not stack-safe for large inputs due to its non-tail-recursive form. To improve performance, we define sumAcc, which uses an explicit accumulator and a tail-recursive helper function to avoid deep call stacks. The theorem sum_correct proves that for any list of natural numbers, sum xs = sumAcc xs. This is mathematically interesting because it confirms—using structural induction and algebraic reasoning—that the transformation preserves meaning across all inputs, not just for a few test cases. In systems programming terms, this is like formally proving that a loop unrolling or inlining optimization didn’t introduce a subtle bug—a capability that’s increasingly essential as code becomes more complex and performance-critical.
import Hello
import Std.Data.List.Basic
open Std
def main : IO Unit := do
IO.println s!"Hello, {hello}!"
IO.println "All proofs have been verified by Lean!"
-- naive, non‑tail‑recursive sum
def sum : List Nat → Nat
| [] => 0
| x :: xs => x + sum xs
-- optimized, tail‑recursive sum using an accumulator
def sumAcc (xs : List Nat) : Nat :=
let rec go (ys : List Nat) (acc : Nat) : Nat :=
match ys with
| [] => acc
| y :: ys => go ys (acc + y)
go xs 0
-- proof that the optimized version agrees with the naive one
theorem sum_correct (xs : List Nat) : sum xs = sumAcc xs := by
induction xs with
| nil =>
-- sum [] = 0, sumAcc [] = go [] 0 = 0
rfl
| cons x xs ih =>
-- sum (x :: xs) = x + sum xs
-- sumAcc (x :: xs) = go (x :: xs) 0 = go xs (0 + x)
-- we simplify and then apply the inductive hypothesis
simp [sum, sumAcc]
-- now we have: x + sum xs = sumAcc xs + x
-- but sumAcc xs = sum xs by ih, and addition is commutative
rw [ih]
If we were to sit down and do the math of this, it’s not straightforward:
We define two functions to compute the sum of a list of natural numbers. The first is a simple recursive version:
This proof ensures that the tail-recursive version retains the exact semantics of the original function—guaranteeing correctness even after performance optimization. It’s a clear example of how Lean can verify low-level loop transformations that might otherwise introduce subtle bugs in traditional systems code.
So all this hurts my head. I’m glad that software is going to do this kinda thing, and a bit in awe of the brilliance of folks who build these tools.
As software complexity grows, formal verification tools like Lean are not merely nice to have—they become essential. Companies and research institutions increasingly adopt Lean to ensure high-quality, reliable code, making Lean skills highly valuable.
Conclusion
Lean isn’t just another programming tool; it’s a powerful ally in your pursuit of correctness and reliability in mathematics and software development. Whether you’re proving intricate mathematical theorems or ensuring your software meets precise specifications, Lean is a valuable skill that promises to shape the future of reliable software and mathematics. And yes, this all complicated, but it’s super powerful, and these are exactly the powers needed as we go into a world with vibe coding, power tools and fully automated build environments. Watch this space.
Hello Gemini Robotics! Google surprised me a couple weeks ago with some cool tech. I’m watching carefully for the events that get AI into hardware and Vision Language Action has a lot of promise in creating more general and adaptable robots. It’s a good name — intelligence that integrates vision, language, and action—allowing robots to understand natural language commands and execute complex tasks in dynamic environments. This represents a move away from narrowly focused, task-specific systems toward robots that can generalize skills across different scenarios.
Google’s PaLM-E debuted in 2023 as one of the first attempts to extend large language models into the robotics domain, using a multimodal setup (text and vision) to instruct simple robot behaviors. While groundbreaking for its time, PaLM-E’s capabilities were limited in terms of task complexity and real-world robustness. Fast-forward to 2025, and Gemini Robotics takes these ideas much further by harnessing the significantly more powerful Gemini 2.0 foundation model. In doing so, Gemini’s Vision-Language-Action (VLA) architecture not only understands language and visual inputs, but also translates them into real-time physical actions. According to DeepMind’s official blog post—“Gemini Robotics brings AI into the physical world”—this new system enables robots of virtually any shape or size to perform a wide range of tasks in dynamic environments, effectively bridging the gap between large-scale multimodal reasoning and real-world embodied intelligence in a way that PaLM-E never could.
However, while its potential is transformative, there are still challenges to overcome in trust and safety, dealing with hardware constraints, and fine-tuning physical actions that might not perfectly align with human intuition.
Introduction
Google DeepMind’s Gemini Robotics is pretty cool. It’s an AI model designed to bring advanced intelligence into the physical world of robots. Announced on March 12, 2025, it represents the company’s most advanced vision-language-action (VLA) system, meaning it can see and interpret visual inputs, understand and generate language, and directly output physical actions. Built on DeepMind’s powerful Gemini 2.0 large language model, the Gemini Robotics system is tailored for robotics applications, enabling machines to comprehend new situations and perform complex tasks in response to natural language commands. This model is a major step toward “truly general purpose robots,” integrating multiple AI capabilities so robots can adapt, interact, and manipulate their environment more like humans do.
Origins and Development of Gemini Robotics
The development of Gemini Robotics is rooted in Google and DeepMind’s combined advances in AI and robotics over the past few years. Google had long viewed robotics as a “helpful testing ground” for AI breakthroughs in the physical realm. Early efforts laid the groundwork: for example, Google researchers pioneered systems like PaLM-SayCan, which combined language models with robotic planning, and PaLM-E, a multimodal embodied language model, hinted at the potential of integrating language understanding with robotic control. In mid-2023, Google DeepMind introduced Robotics Transformer 2 (RT-2), a VLA model that learned from both web data and real robot demonstrations and could translate knowledge into generalized robotic instructions. RT-2 showed improved generalization and rudimentary reasoning – it could interpret new commands and leverage high-level concepts (e.g. identifying an object that could serve as an improvised tool) beyond its direct training. However, RT-2 was limited in that it could only repurpose physical movements it had already practiced; it struggled with fine-grained manipulations it hadn’t explicitly learned.
Gemini Robotics builds directly on these foundations, combining Google’s latest large language model advances with DeepMind’s robotics research. It is built on the Gemini 2.0 foundation model, which is a multimodal AI capable of processing text, images, and more. By adding physical actions as a new output modality to this AI, the team created an agent that can not only perceive and talk, but also act in the real world. The project has been led by Google DeepMind’s robotics division (headed by Carolina Parada) and involved integrating multiple research breakthroughs. According to DeepMind, Gemini Robotics and a companion model called Gemini Robotics-ER were concurrently developed and launched as “the foundation for a new generation of helpful robots”. The models were primarily trained using data from DeepMind’s bi-arm robot platform ALOHA 2 (a dual-armed robotic system introduced in 2024). Early testing was focused on this platform, but the system was also adapted to other hardware – demonstrating control of standard robot arms (Franka Emika robots common in labs) and even a humanoid form (the Apollo robot from Apptronik). This cross-pollination of Google’s large-scale AI (Gemini 2.0) with DeepMind’s embodied AI research culminated in Gemini Robotics, which was formally unveiled in March 2025. Its development reflects a convergence of trends: ever-larger and more general AI models, and the push to make robots more adaptive and intelligent in uncontrolled environments.
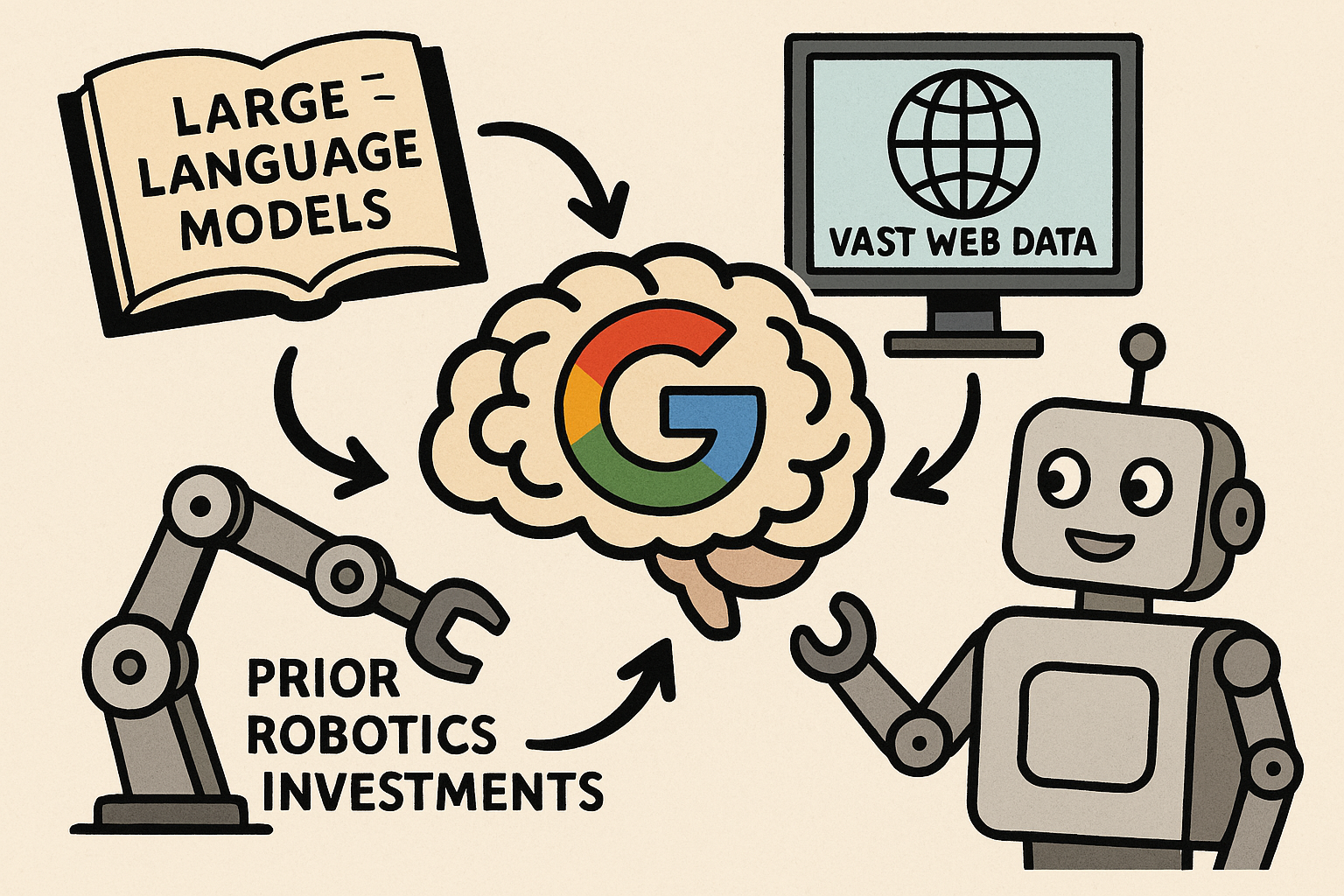
Google DeepMind’s announcement comes amid a “race to make robots useful” in the real world, with several companies striving for similar breakthroughs. Notably, just a month prior, robotics startup Figure AI ended a collaboration with OpenAI after claiming an internal AI breakthrough for robots – underscoring that multiple players are working toward general robotic intelligence (awesome). Within this context, Gemini Robotics emerged as one of the most ambitious efforts, leveraging Google’s unique assets (massive language models, vast web data, and prior robotics investments) to create a generalist “brain” for robots.
The Vision-Language-Action (VLA) Model Explained
At the heart of Gemini Robotics is its vision-language-action (VLA) architecture, which seamlessly integrates perception, linguistic reasoning, and motor control. In practical terms, the model can take visual inputs (such as images or camera feeds of a scene), along with natural language inputs (spoken or written instructions), and produce action outputs that drive a robot’s motors or high-level control system. This tri-modal integration allows a robot equipped with Gemini to perceive its surroundings, understand what needs to be done, and then execute the required steps – all in one fluid loop.
Under the hood, Gemini Robotics leverages the powerful representation and reasoning capabilities of the Gemini 2.0 LLM to interpret both the visual scene and the instruction. The visual input is processed by advanced vision models (DeepMind has indicated that PaLI-X and related vision transformers were adapted as part of earlier systems like RT-2, enabling the AI to recognize objects and understand spatial relationships in the camera view. This is paired with Gemini’s language understanding, which can comprehend instructions phrased in everyday, conversational language – even in different wording or multiple languages. By fusing these inputs, the model forms an internal plan or representation of what action to take. The crucial innovation is that the output is not text, but action commands: Gemini Robotics generates a sequence of motor control tokens or low-level instructions that directly control the robot’s joints and grippers. These action outputs are encoded similarly to language tokens – for example, a series of numeric tokens might represent moving a robotic arm to certain coordinates or applying a specific force. This design treats actions as another “language” for the AI to speak.
An intuitive example of how the VLA model works is the task: “Pick up the banana and put it in the basket.” Given this spoken command, a Gemini-powered robot will use its camera to scan the scene, recognize the banana and the basket (drawing on its visual training), understand the instruction and the desired outcome, and then generate the motor actions to reach out, grasp the banana, and drop it into the basket. All of this can occur without hard-coding specific moves for “banana” or “basket” – the model’s general vision-language knowledge enables it to figure it out. Another striking example demonstrated by Google DeepMind was: “Fold an origami fox.” Without having been explicitly trained on that exact task, the system was able to combine its knowledge of origami (learned from text or images during pre-training) with its ability to control robot hands, successfully folding a paper into the shape of a fox. This showcased how Gemini’s world knowledge can translate into physical skill, even for tasks the robot has never performed before. The VLA architecture effectively allows the robot to generalize concepts to new actions – it “understands” what folding a fox entails and can execute the fine motor steps to do so, all guided by a single natural-language instruction.
Technical Functionality and Capabilities
Gemini Robotics is engineered around three key capabilities needed for versatile robots: generality, interactivity, and dexterity. In each of these dimensions, it represents a leap over previous systems, inching closer to the vision of a general-purpose helper robot.
Generality and World Knowledge: Because it is built atop the Gemini 2.0 model (which was trained on vast internet data and encodes extensive commonsense and factual knowledge), Gemini Robotics can handle a wide variety of tasks and adapt to new situations on the fly. It leverages “Gemini’s world understanding to generalize to novel situations,” allowing it to tackle tasks it never saw during training. For example, researchers report that the model-controlled robot could perform a “slam dunk” with a toy basketball into a mini hoop when asked – despite never having seen anything related to basketball in its robot training data. The robot’s foundation model knew what a basketball and hoop are and what “slam dunk” means conceptually, and it could connect those concepts to actual motions (picking up the ball and dropping it through the hoop) to satisfy the command. This kind of cross-domain generalization – applying knowledge from one context to a new, embodied scenario – is a hallmark of Gemini Robotics. In quantitative terms, Google DeepMind noted that Gemini Robotics more than doubled performance on a comprehensive generalization benchmark compared to prior state-of-the-art VLA models. In other words, when tested on tasks, objects, or instructions outside its training distribution, it succeeded more than twice as often as earlier models. This suggests a significant improvement in robustness to novel situations.
Interactivity and Adaptability: Gemini Robotics is designed to work collaboratively with humans and respond dynamically to changes in the environment. Thanks to its language proficiency, the robot can understand nuanced instructions and even follow along in a back-and-forth dialogue if needed. The model can take instructions given in different ways. Crucially, it also demonstrates real-time adaptability: it “continuously monitors its surroundings” and can adjust its plan if something changes mid-task. An example shown by researchers involved a robot told to place a bunch of grapes into a specific container. Midway through, a person shuffled the containers around on the table. Gemini’s controller tracked the target container as it moved and still completed the task, successfully following the correct container in a game of three-card monte on the fly. This shows a level of situational awareness and reactivity that previous static plans would fail at. If an object slips from the robot’s grasp or is moved by someone, the model can quickly replan its actions and continue appropriately. In practical terms, this makes the robot much more resilient in unstructured, dynamic settings like homes or workplaces, where surprises happen regularly. Users can also update instructions on the fly – for instance, interrupt a task with a new command – and Gemini will smoothly transition, a quality of “steerability” that is important for human-robot collaboration.
Dexterity and Physical Skills: A standout feature of Gemini Robotics is its level of fine motor control. Many everyday tasks humans do – buttoning a shirt, folding paper, handling fragile objects – are notoriously hard for robots because they require precise force and coordination. Gemini Robotics has demonstrated advanced dexterity by tackling multi-step manipulation tasks that were previously considered out of reach for robots without extensive task-specific programming. In tests, its dual-armed system could fold an origami crane, pack a lunchbox with assorted items, carefully pick a single card from a deck without bending others, and even seal snacks in a Ziploc bag. These examples illustrate delicate handling and coordination of two arms/hands – akin to human bimanual tasks. Observers noted that this capability appears to “solve one of robotics’ biggest challenges: getting robots to turn their ‘knowledge’ into careful, precise movements in the real world”. It’s important to note, however, that some of the most intricate feats were achieved in the context of tasks the model was trained on with high-quality data, meaning the robot had practice or human-provided demonstrations for those specific skills. As IEEE Spectrum reported, the impressive origami performance doesn’t yet mean the robot will generalize all dexterous skills – rather, it shows the upper bound of what the system can do when given focused training on a fine motor task. Still, compared to prior systems that could barely grasp a single object reliably, Gemini’s leap to complex manipulation is a significant advancement.
Multi-Embodiment and Adaptability to Hardware: Another technical strength of Gemini Robotics is its ability to work across different robot form factors. Rather than being tied to one specific robot model or configuration, the Gemini AI was trained in a way that makes it adaptable to “multiple embodiments”. DeepMind demonstrated that a single Gemini Robotics model could control both a fixed bi-arm platform and a humanoid robot with very different kinematics. The team trained primarily on their ALOHA 2 twin-arm system, but also showed the model could be specialized to operate the Apptronik “Apollo” humanoid – which has arms, hands, and a torso – to perform similar tasks in a human-like form. This hints at a future where one core AI could power many kinds of robots, from warehouse picker arms to home assistant humanoids, with minimal additional training for each. Google has in fact partnered with Apptronik and other robotics companies as trusted testers to apply Gemini in different settings. The generalist nature of the model means it encodes abstract skills that can transfer to new bodies. Of course, some calibration is needed for each hardware – the system might need to learn the dynamics and constraints of a new robot – but it doesn’t need to learn the task from scratch. This is a big efficiency gain: historically, each new robot or use-case required building an AI model almost from zero or collecting a trove of demonstrations, whereas Gemini provides a strong starting point.
Embodied Reasoning (Gemini Robotics-ER): Alongside the main Gemini Robotics model, Google DeepMind introduced Gemini Robotics-ER (with “ER” standing for Embodied Reasoning). This variant emphasizes enhanced spatial understanding and reasoning about the physical world, and it is intended as a tool for roboticists to integrate with their own control systems. Gemini Robotics-ER can be thought of as a vision-language model with an intuitive grasp of physics and geometry – it can look at a scene and infer things like object locations, relationships, or potential affordances. For instance, if shown a coffee mug, the model can identify an appropriate grasping point (the handle) and even plan a safe approach trajectory for picking it up. It marries the perception and language skills of Gemini with a sort of built-in physics engine and even coding abilities: the model can output not only actions but also generated code or pseudo-code to control a robot, which developers can hook into low-level controllers. In tests, Gemini-ER could perform an end-to-end robotics pipeline (perception → state estimation → spatial reasoning → planning → control commands) out-of-the-box, achieving 2-3× higher success rates on certain tasks compared to using Gemini 2.0 alone. A striking feature is its use of in-context learning for physical tasks – if the initial attempt isn’t sufficient, the model can take a few human-provided demonstrations as examples and then improve or adapt its solution accordingly. Essentially, Robotics-ER acts as an intelligent perception and planning module that can be plugged into existing robots, complementing the primary Gemini Robotics policy which directly outputs actions. By separating out this embodied reasoning component, DeepMind allows developers to leverage Gemini’s spatial intelligence even if they prefer to use their own motion controllers or safety constraints at the execution layer. This two-model approach (Gemini Robotics and Robotics-ER) gives flexibility in deployment – one can use the full end-to-end model for maximum autonomy, or use the ER model alongside manual programming to guide a robot with high-level smarts.
Safety Mechanisms: Given the high level of autonomy Gemini Robotics enables, safety has been a paramount concern in its functionality. The team implemented a layered approach to safety, combining traditional low-level safety (e.g. collision avoidance, not exerting excessive force) with higher-level “semantic safety” checks. The model evaluates the content of instructions and the consequences of actions before executing them, especially in the Robotics-ER version which was explicitly trained to judge whether an action is safe in a given scenario. For example, if asked to mix chemicals or put an object where it doesn’t belong, the AI should recognize potential hazards. DeepMind’s head of robotic safety, Vikas Sindhwani, explained that the Gemini models are trained to understand common-sense rules about the physical world – for instance, knowing that placing a plush toy on a hot stove or combining certain household chemicals would be unsafe. To benchmark this, the team introduced a new “Asimov” safety dataset and benchmark (named after Isaac Asimov, who famously penned robot ethics rules) to test AI models on their grasp of such common-sense constraints. The Gemini models reportedly performed well, answering over 80% of the safety questions correctly. This indicates the model usually recognizes overtly dangerous instructions or outcomes. Additionally, Google DeepMind has implemented a set of governance rules (“robot constitution”) for the robot’s behavior, inspired by Asimov’s Three Laws of Robotics, which were expanded into the ASIMOV dataset to train and evaluate the robot’s adherence to ethical guidelines. For instance, rules might include not harming humans, not damaging property, and prioritizing user intent while obeying safety constraints. These guardrails, combined with ongoing human oversight (especially during testing phases), aim to ensure the powerful capabilities of Gemini Robotics are used responsibly and do not lead to unintended harm.
Is Gemini Robotics the Future of Robotics?
So are we done? Time for our robot overlords? The introduction of Gemini Robotics has sparked debate about whether large VLA models like this represent the future of robotics – a future where robots are generalists rather than specialists, and where intelligence is largely driven by massive pretrained AI models. Google DeepMind certainly positions Gemini as a game-changer, stating that it “lays the foundation for a new generation of helpful robots” and touting its success on previously impossible tasks. Many experts see this as a natural evolution: as AI systems have achieved human-level (and beyond) performance in language and vision tasks, it was inevitable that those capabilities would be extended to physical machines. Generative AI models are getting closer to taking action in the real world, notes IEEE Spectrum, and the big AI companies are now introducing AI agents that move from just chatting or analyzing images to actually manipulating objects and environments. In this sense, Gemini Robotics does appear to be a glimpse of robotics’ likely trajectory – one where embodied AI is informed by vast prior knowledge and can be instructed as easily as talking to a smart speaker. The ability to simply tell a robot what to do in natural language (e.g. “please tidy up the kitchen” or “assemble this Ikea chair”) and have it figure out the steps is a long-standing dream in robotics, and Gemini’s demos suggest we are closer than ever.
Proponents argue that such generalist models are necessary to break robotics out of its current limits. Up to now, most robots excel only in narrow domains (an industrial arm can repeat one assembly task all day, a Roomba can vacuum floors but do nothing else, etc.). To be broadly useful in human environments, robots must deal with endless variability – new objects, unforeseen situations, and evolving human instructions. Hard-coding every contingency or training a custom model for every task is impractical. Therefore, an AI that can leverage world knowledge and reason on the fly is needed. Google’s team emphasizes that all three qualities – generalization, adaptability, dexterity – are “necessary… to create a new generation of helpful robots” that can actually operate in our homes and workplaces. In other words, without an AI like Gemini, robots would remain too rigid or labor-intensive to program for the messy real world. By giving robots a “common sense” understanding of the world and the ability to learn tasks from description, Gemini Robotics indeed could be a cornerstone for future robotics platforms.
That said, whether Gemini’s approach is the future or just one branch is still a matter of discussion. Some robotics researchers caution against over-relying on massive pretrained models. One limitation observed even in Gemini is that its human-like biases may not always yield optimal physical decisions. For example, Gemini-ER identified the handle of a coffee mug as the best grasp point – because in human data, people hold mugs by handles – but for a robot hand, especially one immune to heat, grabbing the sturdy body of the mug might actually be more stable than the thin handle. This shows that the AI’s “common sense” is derived from human norms, which isn’t always ideal for a machine’s capabilities. Overcoming such discrepancies may require integrating pure learning from trial and error or additional physical reasoning beyond internet-based knowledge. Additionally, the most dexterous feats Gemini achieved were ones it specifically trained for with high-quality demonstrations. This indicates that while the model is general, it still benefits from practice on complex tasks – true one-shot generalization to any arbitrary manipulation is not fully solved. In essence, Gemini Robotics might be necessary but not sufficient for the future of robotics: it provides the intelligence and adaptability, but it must be paired with continued advances in robot hardware and in task-specific learning.
Another consideration is the computational complexity. Gemini 2.0 (the base model) is extremely large, and running such models in real-time on a robot can be challenging. Currently, much processing might happen on cloud servers or off-board computers. The future of robotics may depend on making these models more efficient (something Google is also addressing with smaller variants like “Gemma” models for on-device AI. The necessity of a model like Gemini might also depend on the application: for a general home assistant or a multipurpose factory robot, a broad intelligence is likely crucial. But for simpler, well-defined tasks (say, a robot that just sorts packages), a smaller specialized AI might suffice more economically. Therefore, we might see a hybrid future – in high-complexity domains, Gemini-like brains lead the way, whereas simpler robots use more lightweight solutions. Nonetheless, the techniques and learnings from Gemini (like treating actions as language tokens, and using language models for planning) are influencing the entire field. Competing approaches will likely incorporate similar ideas of multi-modal learning and large-scale pre-training because of the clear gains in capability that Gemini and its predecessors have demonstrated. In summary, Gemini Robotics does appear to be a harbinger of robotics’ future, providing a path to move beyond single-purpose machines. Its advent underscores a paradigm shift where generalist AI systems control robots – a notion that until recently belonged to science fiction – and it illustrates both the promise and the remaining challenges on the road to truly adaptive, helpful robots.
Comparisons to Alternative Approaches in Robotic AI
Gemini Robotics’s approach can be contrasted with several other strategies in robotic AI, each with its own philosophy and trade-offs. Below, we compare it to some notable alternatives:
Modular Robotics (Traditional Pipeline): The classic approach to robot intelligence breaks the problem into separate modules: perception (computer vision to detect objects, SLAM for mapping), decision-making (often rule-based or using a planner), and low-level control (path planning and motor control). In such systems, there isn’t a single monolithic AI “brain” – instead, engineers program each component and often use specific AI models for each (like a convolutional network for object recognition, a motion planner for navigation, etc.). The advantage is reliability and predictability; each module can be tuned and verified. However, the drawback is rigidity – the robot can only do what its modules were explicitly designed for. Adding new tasks requires significant re-engineering. In contrast, Gemini Robotics is more of an end-to-end learned system. It attempts to handle perception, reasoning, and action generation in one model (or at least with tightly integrated learned components). This holistic approach allows for more flexibility – e.g. interpreting an unfamiliar instruction and devising a behavior – which a modular system might not handle if not pre-programmed. Of course, Gemini still relies on some low-level controllers (for fine motion, safety constraints), but the boundary between modules is blurred compared to the traditional pipeline. Essentially, Gemini trades some transparency for vastly greater adaptability. As robots move into unstructured environments, this trade is often seen as worthwhile, because no team of engineers can anticipate every scenario the way a large trained model can generalize.
Reinforcement Learning and Imitation Learning: Another approach is to teach robots via trial and error (RL) or by imitating human demonstrations, training a policy neural network for specific tasks. OpenAI famously used reinforcement learning plus human teleoperation demos to train a robot hand to solve a Rubik’s Cube, and Boston Dynamics uses a mix of planning and learned policies for locomotion. These systems can achieve remarkable feats, but they are typically narrow in scope – the policy is an expert at one task or a set of related tasks. Gato, a 2022 DeepMind model, was an attempt at a multi-task agent (it learned from dozens of different tasks, from playing Atari games to controlling a robot arm), but even Gato had a fixed set of skills defined by its training data. Gemini Robotics differs by leveraging pretrained knowledge: rather than learning from scratch via millions of trials, it starts with a rich base of semantic and visual understanding from web data. This gives it a form of “common sense” and language ability out-of-the-box that pure RL policies lack. In essence, Gemini moves the needle from “learning by doing” to “learning by reading/seeing” (plus some doing). That means a Gemini-based robot might execute a new task correctly on the first try because it can reason it out, whereas an RL-based robot would likely flail until it accumulates enough reward feedback. The flip side is that RL can sometimes discover unconventional but effective strategies (since it isn’t constrained by human priors), and it can optimize for physical realities (dynamics, wear and tear) if given direct experience. A future approach might combine both: use models like Gemini for high-level reasoning and understanding, but allow some reinforcement fine-tuning on the robot itself to refine the motions for efficiency or reliability. In fact, fine-tuning Gemini on robotic data (like how RT-2 was fine-tuned on real robot experiences is exactly what Google did, and further RL training could be a next step beyond the initial demo capabilities.
Other Foundation Model Approaches: Google is not alone in applying foundation models to robotics. Competitors and research labs are pursuing similar visions. For example, OpenAI has been exploring ways to connect its GPT-4 model to robotics (though no official product has been announced, internal experiments and partnerships have been noted). The startup Figure AI, which is building humanoid robots, initially partnered with OpenAI to leverage GPT-style intelligence, but as Reuters reported, Figure decided to develop its own model after making an internal breakthrough. This suggests that a number of players are working on language-model-driven robotics, each with their own twist. Another example is Microsoft and Google’s PaLM-E (embodied language model) which was a precursor integrating a vision encoder with a language model to output robot actions. Meta (Facebook) has also done research on combining vision, language, and action – though they’ve been quieter in announcing a unified model, they have components like visual question answering and world model simulators that could feed into robotics. There is also a distinction in whether the model is end-to-end or generates code for the robot. Some approaches have the AI output code (in Python or a robot API) which is then executed by a lower system – this can be safer in some cases, as the code can be reviewed or sandboxed. Gemini-ER’s ability to produce code for robot control falls into this category. Companies like Adept AI take a similar approach for software automation (outputting code from instructions); applied to robotics, one could imagine an AI that writes a script for the robot (e.g. using a library like ROS – Robot Operating System – to move joints) rather than directly controlling every torque. The drawback is that if the situation deviates, the code might not handle it unless the AI is looped in to rewrite it. Gemini’s direct policy is more fluid, but code-generation approaches offer interpretability.
In comparison to these alternatives, Gemini Robotics distinguishes itself by its scale of general knowledge and its demonstrated range of capabilities without task-specific training. A Tech Review article headline concisely states it “uses Google’s top language model to make robots more useful,” implying that plugging in this very large pre-trained brain yields a robot that can do far more than ones programmed with only task-specific data. Moreover, Gemini was shown to operate “with minimal training” for new tasks – many instructions it can execute correctly the first time, thanks to its prior knowledge. This sets it apart from typical RL or modular systems which often need extensive data or engineering for each new behavior. However, it’s worth noting that alternative approaches are converging. For instance, Robotics Transformer (RT-2), while smaller in scope, was already a VLA model and Gemini is essentially the next evolution. So rather than completely different paradigms, we are seeing a merging: classical robotics brings the safety and control expertise, while new AI brings flexibility. The future likely involves integrating these approaches – indeed Google’s strategy with Gemini-ER is to let developers use their own controllers alongside the AI, marrying learned reasoning with trusted control algorithms.
From an industry perspective, the availability of models like Gemini Robotics can level the playing field for robotics companies. Instead of needing a large AI team to build a robot’s brain from scratch, startups can leverage a frontier model (via API or licensing) and focus on hardware and specific applications. Google asserts that such models can help “cash-strapped startups reduce development costs and increase speed to market” by handling the heavy AI lifting. Similar services may be offered by cloud providers (e.g. Nvidia’s ISAAC system, etc.). In contrast, some companies might prefer to develop their own AI to avoid dependency – as seen by Figure’s move away from OpenAI. Competitors like Tesla are also working on general-purpose humanoid robots (Tesla’s Optimus) but with a philosophy leaning on vision-based neural networks distilled from human demonstrations (as per Tesla’s AI Day presentations) – an approach less language-oriented than Gemini’s, at least publicly. It remains to be seen which approach yields better real-world performance and safety.
In summary, Gemini Robotics exemplifies the large-scale, knowledge-rich, end-to-end learning approach to robotic AI. Alternative approaches exist on a spectrum from hand-engineered to learning-based, and many are gradually incorporating more AI-driven generality. The consensus in the field is that to achieve human-level versatility in robots, some form of massive, generalist AI is required – whether it’s exactly Gemini or something akin to it. As of now, Gemini Robotics stands at the cutting edge, but it will no doubt inspire both open-source and commercial efforts that use similar techniques to push robotics forward.
Gemini Robotics represents a bold leap forward in the quest to endow robots with general intelligence and adaptability. By fusing vision, language, and action, it allows machines to see the world, reason about it with human-like understanding, and act to carry out complex tasks – all guided by natural language. The origins of this model lie in years of incremental progress (from multi-modal models to robotic transformers) that have now converged into an embodied AI agent unlike any before. Technically, Gemini’s VLA model demonstrates unprecedented capabilities: it can generalize knowledge to new situations, interact fluidly with humans and dynamic environments, and perform fine motor skills once thought too difficult for robots without extensive programming. These achievements inch us closer to the long-envisioned general-purpose robot helper.
Yet this is not an endpoint but a starting point for the next era of robotics. Gemini Robotics does appear to chart the future: a future where intelligent robots can be taught with words and examples, not just hard-coded instructions, and where they can work alongside people in everyday environments. Its approach is likely to influence most robotic AI strategies going forward, whether through direct usage or through the adoption of similar large-model techniques by others. At the same time, the necessity of such powerful AI in robots also brings into focus the responsibilities that come with it. Ensuring safety, aligning actions with human values, and considering the societal impact are as integral to this future as the algorithms themselves.
In comparing Gemini to other approaches, we see that while alternative methods exist (from classical robotics to reinforcement learning), the field is coalescing around the idea that scale and generality in AI are key to cracking the hardest robotics challenges. Gemini’s current edge in performance (reportedly doubling previous systems on generalization benchmarks) validates this direction. But it also highlights that cooperation between human engineers and AI will remain crucial – whether for fine-tuning dexterous skills, implementing safety constraints, or adapting the model to new robot hardware. The “brain” may be general, but the implementation details and guarantees still require human ingenuity and caution.
Training for a Half Ironman (70.3) is equal parts endurance, nutrition, and smart pacing. Over the last few months, I’ve spent countless hours in the pool (plus on the bike and run) to prepare. Below is the nutrition and timing strategy I’m trying out for race day.
I normally like to show my work, but I pulled all my Strava/training data into postgres, used sql to get all my run, bike, and swim data over the last year and did some regressions to understand my pace with common formulas. This post is just the plan, the code, etc is in other posts.
Based on recent ~2–2.5 km swims, I’m estimating 40 minutes for the 1.2‑mile portion. That’s a comfortable pace—fast enough to set up a solid bike, but not so hard that I’m gasping in transition.
I’m guessing 3 minutes or so for transition, factoring in wetsuit removal and the hustle to the bike. My training rides suggest an average 16–17 mph pace over rolling terrain. This translates to 3 hr 15 min–3 hr 30 min for the race, depending on conditions (wind, elevation, etc.). Guessing ~2 minutes to rack the bike, throw on running shoes, and grab nutrition. From run data, I’m aiming for ~8:30–9:00 per mile pace off the bike, targeting 1:50–2:00. If I nail the bike intensity and nutrition, I should stay closer to 1:50–1:55. Overall, that means ~6 hours total, give or take 15–30 minutes, depending on transitions, weather, and race‑day magic. Bah, I think I can do so much better, but this is the attempt.
My fueling strategy focuses on sustaining consistent carbohydrate intake throughout the race by aiming for around 60–90 grams of carbs per hour on the bike, then scaling down slightly to 40–60 grams per hour on the run. To achieve this, I prepared each 750 mL Gatorade bottle with approximately 80 grams of carbohydrate (mixing six tablespoons, or about three‑eighths of a cup of powder), providing 320 calories per bottle.
To save anyone else the time, I’m showing my math for one thing, nutrition.
To ensure each of my \( 750\,mL \) bottles contains approximately \( 80\,g \) of carbohydrates, I used the nutritional information on my Gatorade container. The container specifies a relationship between tablespoons (Tbsp), milliliters (mL), and grams of carbohydrates:
Therefore, by adding roughly 6 tablespoons of Gatorade powder (about 3/8, cup or 90 mL of powder) to 750 mL of water, I obtain a mix that delivers about 80g of carbohydrates (and roughly 320kcal). This mixture provides a consistent carbohydrate concentration (approximately 6–8%), which is both palatable and effective for fueling during long training sessions or races.
Drinking one bottle per hour meets my baseline carb goal of about 80 grams per hour on the bike. For additional carbohydrate or if I want to reach closer to 90 grams per hour, I incorporate Maurten gels that each provide roughly 25 grams of carbs. These gels also become key during the run, where I take one every 20–30 minutes to match my target of 40–60 grams of carbs per hour.
Recent sweat tests show that my fluid loss rate varies significantly with both temperature and activity intensity. For example, a higher‑intensity run in warm, dry conditions (76 °F and 28% humidity) resulted in losing about 3.1 lb of body weight in just over an hour—roughly 1.4 L (48 oz) per hour. Conversely, a cooler bike session (53 °F, 68% humidity) saw losses closer to 1.0 L (34 oz) per hour, while a shorter ride at 54 °F and 69% humidity required only about 0.5 L (16–17 oz) per hour. These data suggest I should plan fluid intake anywhere between 0.5 and 1.4 L per hour, depending on the temperature, humidity, and how hard I’m pushing.
Given all this, I plan to drink around 24 ounces (one 750 mL bottle) per hour while cycling, then switch to 12–20 ounces per hour on the run. Gatorade supplies a good amount of sodium and it’s a cool 56 degrees tomorrow so I don’t need more.
I had a carb‑rich dinner the tonight, followed by a light breakfast containing about 80–100 grams of carbs two to three hours before the start, plus 16–20 ounces of fluid to begin the day well‑hydrated. In transition one, I can take an extra gel if I feel I need a boost before heading out on the bike, and transition two simply involves a quick fluid sip, changing shoes, and picking up the gels I’ll need on the run.
Let’s see how this goes …. Ok. Race report. The swim was cancelled since the water was too choppy. Disappointing. Additionally, it was pouring monsoon bad at the start. It was confusing. The whole transition zone was empty with people walking their bikes away. Folks were taking shelter next to the port a potties. I got soaked and sought refuge in the nearby hotel.
When the race started, I was surprised to be passing a lot of folks in fancy bikes with those cool aero helmets. Using the aero bars wasn’t that comfortable and with a 30mph crosswind, the bike was sliding around. Lots of folks were fixing flats and the course had some crazy sharp turns and narrow sections. The worst was the bridge where I was on the very edge of stability.
The overriding dynamic was that I needed to pee. Like miles 18 to 26, then miles 48 to 56 were intensely uncomfortable. The only option was two longer waits for a temp toilet. The impact was that the aero bars were super uncomfortable. Despite the wind, etc. I nailed my time with 3 hr ride and convinced I could have done 20 min faster if I could keep fluids in and not be so afraid of the aero bars. My average heart rate was around 120, lots of room to go faster. Power was around 200W. Nutrition was incredible. Never hungry, tank was full. Just too full of water.
The run was awesome. Just cranked in 7:30s and counted down the miles with HR around 165 to 170. Ended with lots in the tank and did a couple mile cool down on the bike. Watch time was 1:38 for the 1/2 marathon.
Now time to get better at this. This was way way different than my ultra.
Jeukendrup, A. E. (2014). A step towards personalized sports nutrition: carbohydrate intake during exercise. Sports Medicine, 44(Suppl 1), 25–33.
Burke, L. M., Hawley, J. A., Wong, S. H., & Jeukendrup, A. E. (2011). Carbohydrates for training and competition. Journal of Sports Sciences, 29(sup1), S17–S27.