Decoding Operator Intent: The Future of Multi-Agent Goal Inference in Robotics

One of the coolest challenges in robotics is to enabling machines to grasp the bigger picture from a small bit of human control. Imagine an operator guiding a single robot in a complex environment—the robot isn’t just executing isolated commands, but is part of a larger, dynamic mission. This is where multi-agent goal inference steps in. It’s the art and science of decoding an operator’s intent from local, granular actions to infer global mission objectives.
Think of this as “zooming out” from a single, localized action to reveal a much larger, underlying structure. It aways seems magical when AI allows the transformation of low-resolution images into high-resolution outputs by inferring structure. In other words, by carefully analyzing small, seemingly isolated inputs—such as an operator’s control over one robot—an intelligent system can infer the broader mission or goal structure. This process involves recognizing patterns and connections that aren’t immediately obvious from the initial, “small” piece of information. It’s inferring structure.

Multi-agent goal inference is a necessary part of multi-agent systems. A robot might receive only a simple command or a series of minor adjustments, yet these inputs can be extrapolated into a comprehensive understanding of the overall objective. This “explosive” inference transforms localized signals into a richer, more complex picture, enabling distributed agents to coordinate, adapt, and execute large-scale missions without explicit instructions for every detail. It’s cool.
This capability essentially mirrors a fundamental aspect of human cognition: we often infer context and structure from very short interactions. As researchers integrate probabilistic reasoning, inverse planning, and learning-based methods, robotic systems are beginning to exhibit a similar aptitude—expanding a small set of observations into a detailed, coherent plan that drives robust multi-agent cooperation.
The core challenge lies in bridging the gap between an operator’s limited, localized inputs and the expansive, often unpredictable goals of a mission. Reality is messy and unpredictable. Traditional control systems require explicit instructions for every step, but what if robots could intuit the next moves based on subtle cues? Recent insights suggest that AI systems must evolve to anticipate broader mission objectives through small-scale interactions. In essence, the robots of tomorrow should be able to read between the lines, inferring tasks without needing every detail spelled out.
The future of this technology is anchored in developing probabilistic goal inference models. These models are designed to dynamically adjust to real-time changes, enabling a seamless translation of an operator’s intentions into coordinated actions among multiple robotic agents. If implemented correctly, machines will not only be responsive but also intuitively proactive in complex, unpredictable environments. A simple example can show the math of how this can work.
Let:- \(G\) is the set of possible goals.
- \(a_{1:T}\) is the observed sequence of actions.
- \(P(g)\) is the prior probability of goal \(g\).
- \(P(a_{1:T} \mid g)\) is the likelihood of observing actions \(a_{1:T}\) given goal \(g\).
Today’s robotics research is taking a multifaceted approach to multi-agent goal inference—particularly when an operator’s localized control over a single robot must be extrapolated to infer broader mission objectives. Researchers are tackling this challenge with techniques that blend classical planning, probabilistic reasoning, and cutting-edge machine learning.
One popular strategy is to view goal inference as an inverse planning problem. By assuming that each agent acts approximately rationally, methods based on Bayesian inverse planning and inverse reinforcement learning infer the operator’s underlying intent from observed actions. For example, Ramírez and Geffner frame goal recognition as “planning in reverse,” where the cost differences between observed behaviors and optimal plans help compute the likelihood of different mission goals . These methods have been refined to handle noisy or partial observations, enabling robots to update their belief about the global objective in real time.
Recent advances have also emphasized interactive inference, where agents not only execute commands but also actively communicate their intentions through both verbal and non-verbal cues. Models of interactive inference allow agents to observe the actions and even the language used by human operators or teammate robots to collaboratively infer the overarching goal . Such approaches—often inspired by human teamwork dynamics—demonstrate that integrating sensorimotor communication can accelerate goal inference and reduce uncertainty.
In another line of research, Domenico Maisto, Francesco Donnarumma, and Giovanni Pezzulo propose a multi‑agent model of cooperative joint actions where agents iteratively update their beliefs about the shared goal through mutual observation. This “interactive inference” framework enables agents to align their internal structures from simple, local signals into a cohesive team plan.
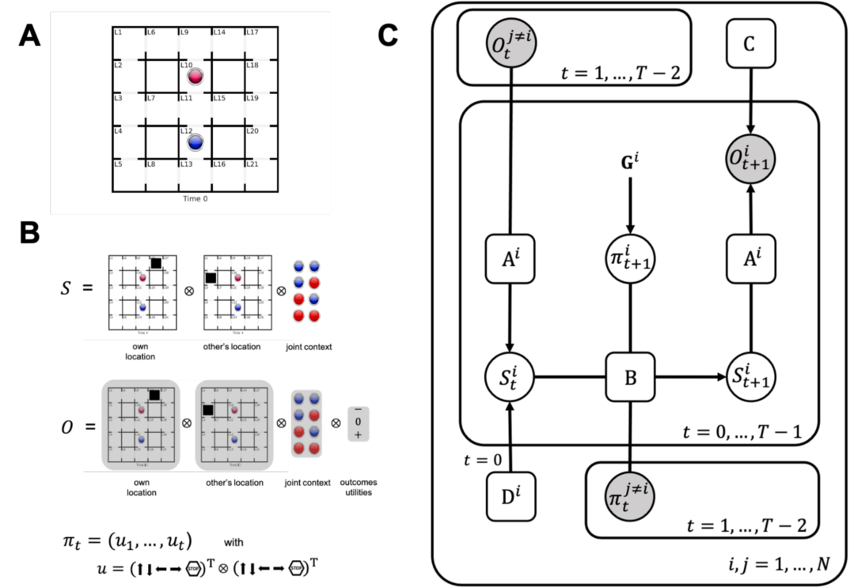
At the University of Washington, a research team developed ColorGrid, a novel multi‑agent environment that simulates dynamic goals. In ColorGrid, a “follower” agent must infer the leader’s goal solely by observing its trajectory, illustrating how minimal, localized inputs can be expanded into an understanding of complex, shifting objectives.
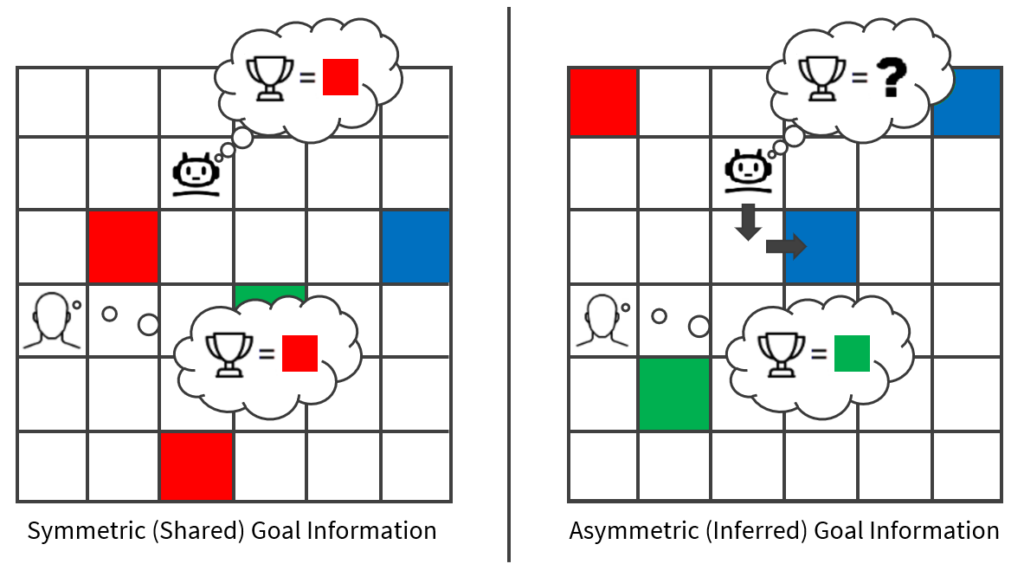
Cognizant’s Neuro® AI Multi-Agent Accelerator exemplifies how enterprises can implement systems that orchestrate numerous specialized agents to collaborate and align with overarching business goals. Their framework allows businesses to rapidly prototype, customize, and scale multi‑agent networks that transform small, individual actions into coordinated, enterprise‑wide decision-making.
Another exciting avenue is the incorporation of deep learning, particularly large language models (LLMs), into multi-agent systems. These models are being adapted to interpret subtle operator inputs and to translate those into probabilistic estimates of global mission intent. By leveraging the rich contextual understanding of LLMs, researchers are developing systems where the “language” of robot actions becomes a basis for knowledge representation, enhancing robustness in sparse-data environments. In tandem, reinforcement learning frameworks are evolving to allow agents to coordinate and share inferred goals, compensating for hardware limitations with smarter software.
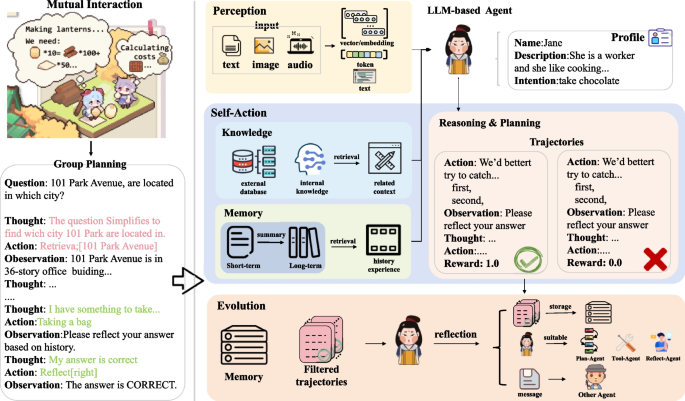
The work by Ying et al. on “Inferring the Goals of Communicating Agents from Actions and Instructions” is a prime example. In that study, researchers used GPT‑3 as a likelihood function to process natural language instructions from a human operator. The model then integrates these instructions with observed actions via Bayesian inverse planning to generate probabilistic estimates of a team’s global mission intent. This approach leverages the rich contextual understanding of large language models (LLMs) to translate subtle operator inputs into high-level goal inferences—effectively turning the “language” of robot actions into a structured knowledge representation. It also demonstrates how reinforcement learning frameworks are evolving to coordinate agents, thereby compensating for hardware limitations with smarter, software‑driven solutions.
Many current systems adopt a hybrid approach that combines heuristic planning with probabilistic inference. Such architectures can dynamically switch between centralized coordination—where a common goal inference model is shared—and decentralized, agent-specific decision-making. This adaptability is critical in mission environments where some robots may fail or new information becomes available, allowing the swarm to reconfigure its strategy without explicit reprogramming.
One cool example of multi-agent navigation tasks is when researchers combine heuristic planning with probabilistic inference to dynamically adapt control strategies. For instance, in some recent multi-agent reinforcement learning (MARL) frameworks, a centralized “goal inference” model is used to establish a common plan when all agents are operating correctly. However, when some robots fail or new, unexpected data arises, the system can switch to a decentralized mode where individual agents use heuristic planning—often informed by local probabilistic reasoning—to reconfigure their strategy. (See the paper by Lowe et al. (2017) titled “Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments” which presents a framework where a centralized “goal inference” critic coordinates agents’ behaviors while individual agents execute decentralized policies based on local information.)
A concrete example comes from research in cooperative multi-agent navigation in dynamic environments. In such systems, a centralized planner might initially coordinate a swarm’s movement based on a shared inference of mission intent, but if communication between agents becomes unreliable or some agents drop out, each remaining agent falls back on its local heuristic planning module, augmented with probabilistic inference to predict nearby agents’ behavior. This hybrid strategy ensures that the team continues to function effectively despite failures or changes in the environment.
Another instance can be seen in emerging robotics platforms used in search and rescue missions. In these systems, a central command may provide a global objective, but each robot is also equipped with local decision-making capabilities that allow it to independently adjust its path and actions using heuristic and probabilistic methods when faced with obstacles or failures in teammates. This dynamic switching between centralized coordination and decentralized planning enables the overall system to maintain mission success without explicit reprogramming.
Multi-agent navigation systems are designed to blend centralized coordination with decentralized decision-making. Many frameworks begin with a central planner that establishes a shared mission intent using probabilistic inference, guiding the coordinated movement of agents. When disruptions occur—such as communication failures or the loss of agents—the system automatically shifts to decentralized control. In these cases, individual agents rely on local heuristic planning, supported by probabilistic reasoning to predict nearby agents’ actions, ensuring continued operational success. This hybrid strategy is effectively applied in fields ranging from reinforcement learning-based swarm robotics to dynamic search and rescue missions.
Be the first to write a comment.