It has been awhile since I’ve studied optimization, but gradient descent is always good to brush up on. Most optimization involves derivatives. Often known as the method of steepest descent, gradient descent works by taking steps proportional to the negative of the gradient of the function at the current point.
Mathematically, gradient descent is defined by an algorithm for two variables, say 
$$ \theta_j := \theta_j – \alpha \frac{\partial J (\theta_0 , \theta_1) }{\partial \theta_j } $$
from the hypothesis:
$$ \begin{aligned}
h_\theta(x) = \sum_{i=1}^n \theta_i x_i = \theta^{T}x.
\end{aligned} $$
The 
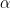
Often for linear regression, we use batch gradient descent. In machine learning terminology, batch gradient descent uses all training examples. This means that for every step of gradient descent, we compare all residuals in the final least squares calculation.
Why is this relevant to machine learning? Of course there is always an analytical solution to any model, but this might involve a very large matrix inversion and be computationally infeasible.
$$ \theta = (X^T X)^{-1} X^T y $$
Gradient descent gets used because it is a numerical method that generally works and is easy to implement and a is very generic optimization technique. Also, analytical solutions are strongly connected to the model, so implementing them can be inefficient if you plan to generalize/change your models in the future. They are sometimes less efficient then their numerical approximations, and sometimes there are simply harder to implement.
To sum up, gradient descent is preferable over an analytical solution if:
- you are considering changes in the model, generalizations, adding some more complex terms/regularization/modifications
- you need a generic method because you do not know much about the future of the code and the model
- analytical solution is more expensive computationaly, and you need efficiency
- analytical solution requires more memory or processing power/time than you have or want to use
- analytical solution is hard to implement and you need easy simple code